vLLM:MoE 模型 Multi-LoRA 推理上线,输出吞吐量提升 454%
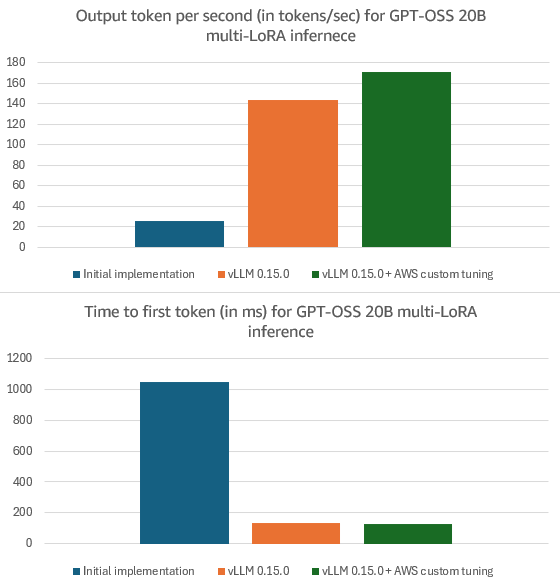
vLLM v0.15.0 与亚马逊合作推出 MoE 模型的 Multi-LoRA 推理功能。GPT-OSS 20B 测试显示输出吞吐量提升 454%、首 token 延迟降低 87%,底层采用 fused_moe_lora 新核心处理复合稀疏性。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。
vLLM v0.15.0 与亚马逊合作推出 MoE 模型的 Multi-LoRA 推理功能。GPT-OSS 20B 测试显示输出吞吐量提升 454%、首 token 延迟降低 87%,底层采用 fused_moe_lora 新核心处理复合稀疏性。
查看原文