Google:Gemma 4 支持四种尺寸、256K 上下文窗口及原生函数调用
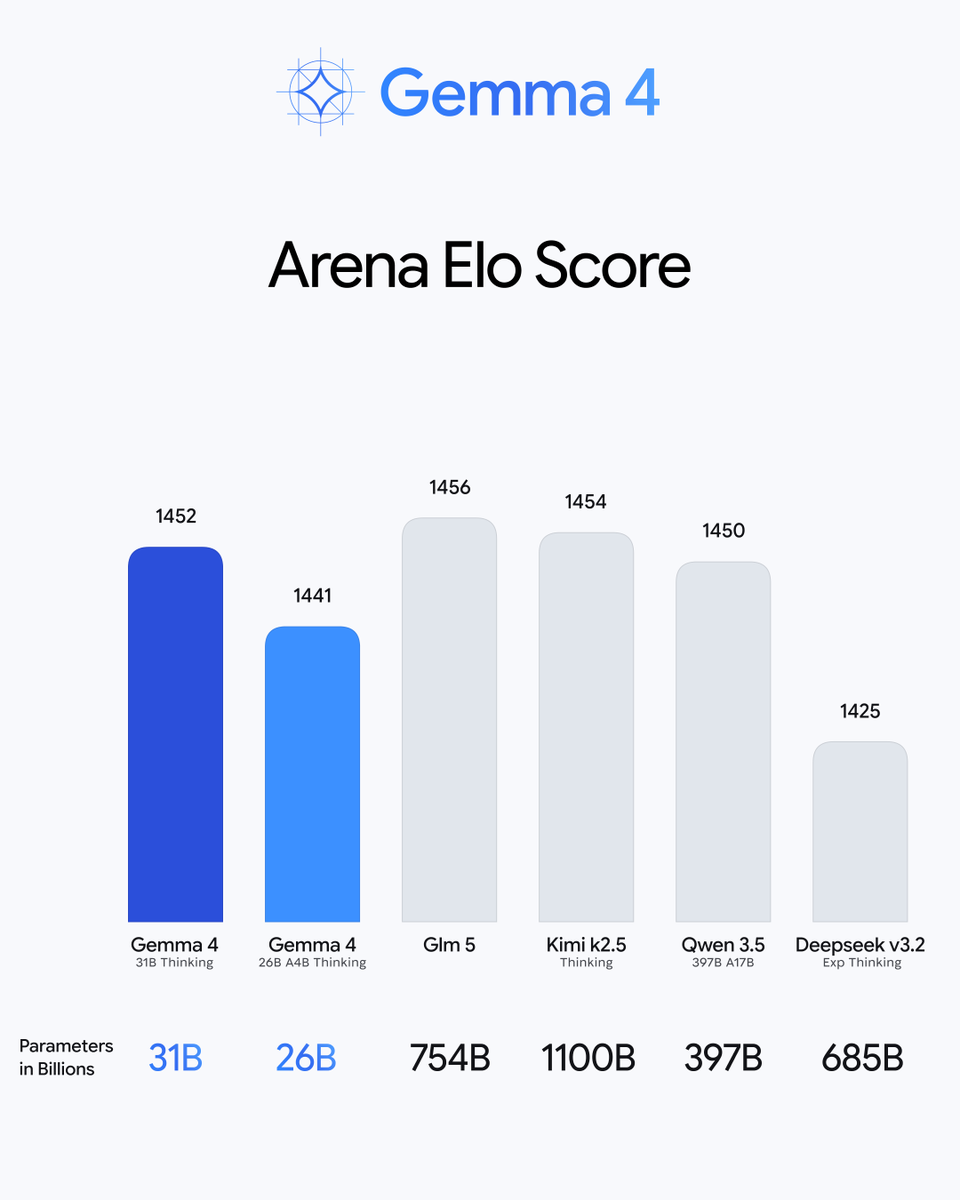
Gemma 4 具体参数:四种尺寸可选,最高 256K 上下文窗口,原生函数调用支持自主 Agent,离线代码生成,原生多模态,支持 140+ 语言。
查看原文Google 发布 Gemma 4,四种规格、最高 256K 上下文窗口、原生函数调用支持自主 Agent。相比 Gemma 3 的 128K 上下文翻倍,并补齐了函数调用能力。开源策略清晰,剑指 Llama/Mistral 的开源小模型市场份额。
Google 正式发布 Gemma 4,这是其开源小模型系列的最新迭代。核心参数层面:四种尺寸规格(从数 B 到数十 B 不等)、最高 256K 上下文窗口(较 Gemma 3 的 128K 直接翻倍)、原生函数调用(Native Function Calling)能力、以及离线的代码生成和多模态支持。
256K 上下文窗口的意义
256K tokens 约等于 20 万汉字,可以完整装入一部中篇小说的文本。这意味着 Gemma 4 能够进行超长文档的精确检索、跨章节的上下文推理,以及复杂代码库的全局分析。对于构建 RAG(检索增强生成)系统的企业用户,超长上下文可以减少分段切割带来的信息损失,提升端到端准确率。
原生函数调用:Agent 时代的基础设施
「原生函数调用支持自主 Agent」是关键能力。这意味着模型能够理解 JSON 格式的工具 schema、正确调用外部 API、并基于返回结果做下一步推理。与之前只能「对话」的模型相比,Gemma 4 具备工具调用闭环,开发者无需再借助复杂的 Prompt 工程来实现 Function Ca
继续阅读深度解读 + 编辑加注
下方还有 3-5 段深度分析 + Vincent 编辑加注 + 可点击信源,仅 Pro 会员可见
¥99 / 季 · 每周 1 篇深度研报 · 飞书+微信群双通道
已是 Pro 但仍被提示?联系反馈
- Google Gemma 4 官方发布 · 2026-04-02
- Gemma Model Card / Documentation · 2026-04-02