Google DeepMind:Gemma 发布四个尺寸,31B Dense 到 Edge 2B 全覆盖
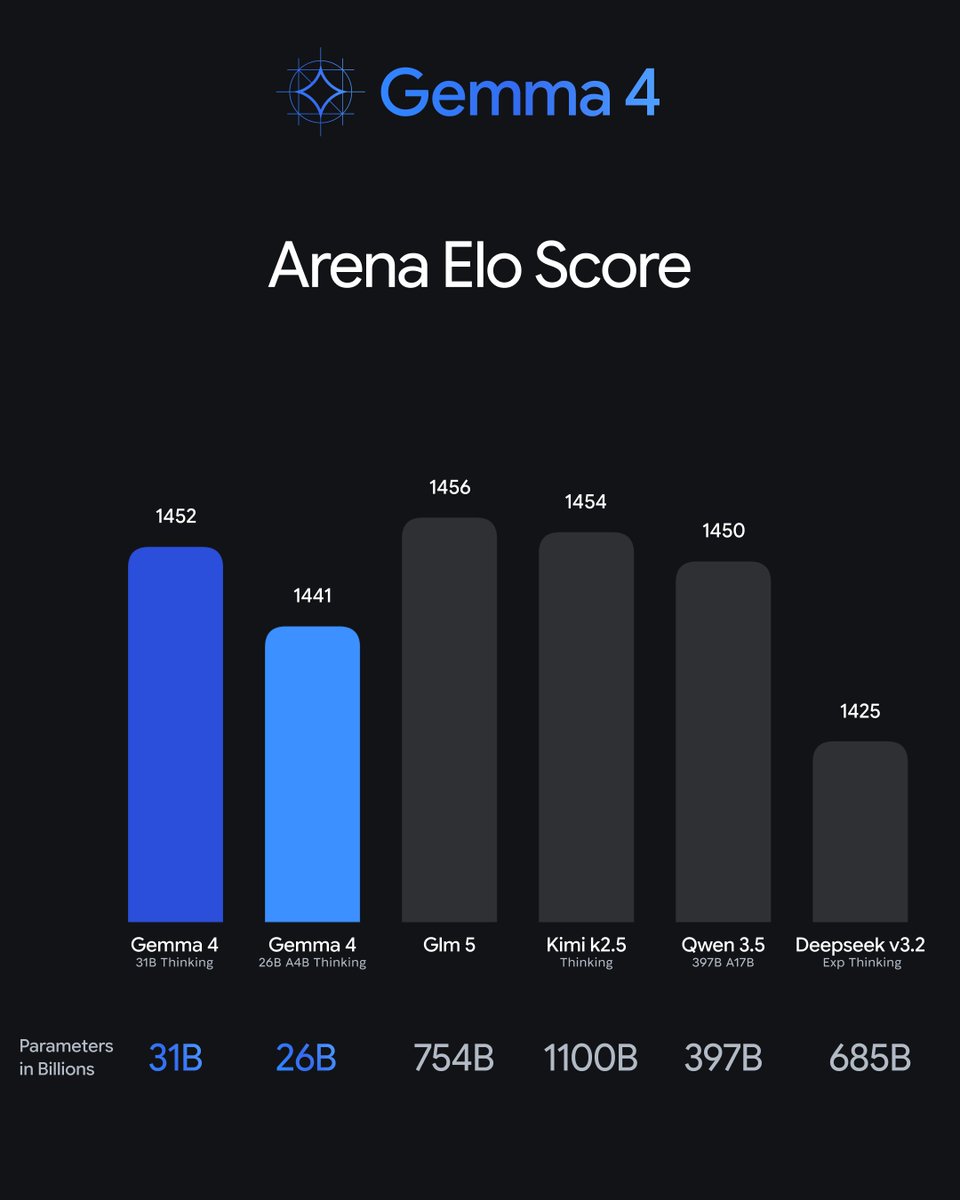
Google DeepMind 发布 Gemma 新版本四个尺寸:31B Dense 和 26B MoE(本地推理)+ E4B 和 E2B(移动端,实时文本/视觉/音频处理)。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。
Google DeepMind 发布 Gemma 新版本四个尺寸:31B Dense 和 26B MoE(本地推理)+ E4B 和 E2B(移动端,实时文本/视觉/音频处理)。
查看原文