vLLM:Gemma 4 正式上线,原生多模态支持、256K 上下文、Apache 2.0 开源
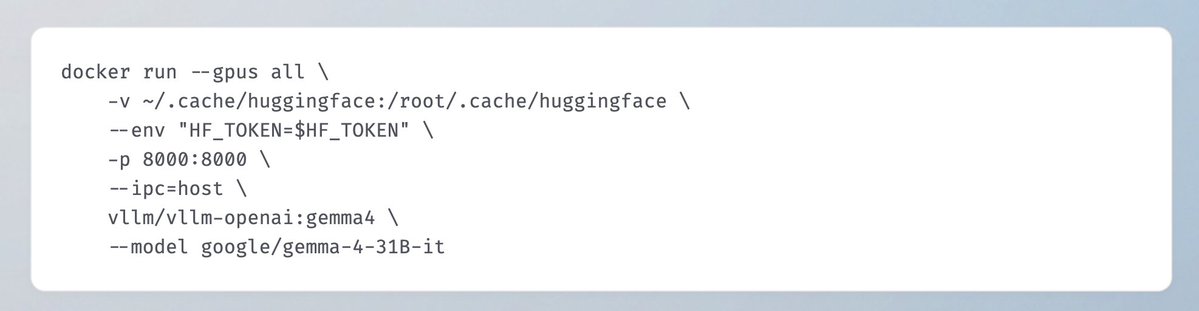
Google 最新开源模型 Gemma 4 已在 vLLM 上可用,支持视觉和音频的原生多模态能力,256K 上下文窗口,首日即支持主流 GPU 架构和 Google TPU,采用 Apache 2.0 许可证。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。
Google 最新开源模型 Gemma 4 已在 vLLM 上可用,支持视觉和音频的原生多模态能力,256K 上下文窗口,首日即支持主流 GPU 架构和 Google TPU,采用 Apache 2.0 许可证。
查看原文