Anthropic:发现 Claude 对话中存在「情感」激活模式
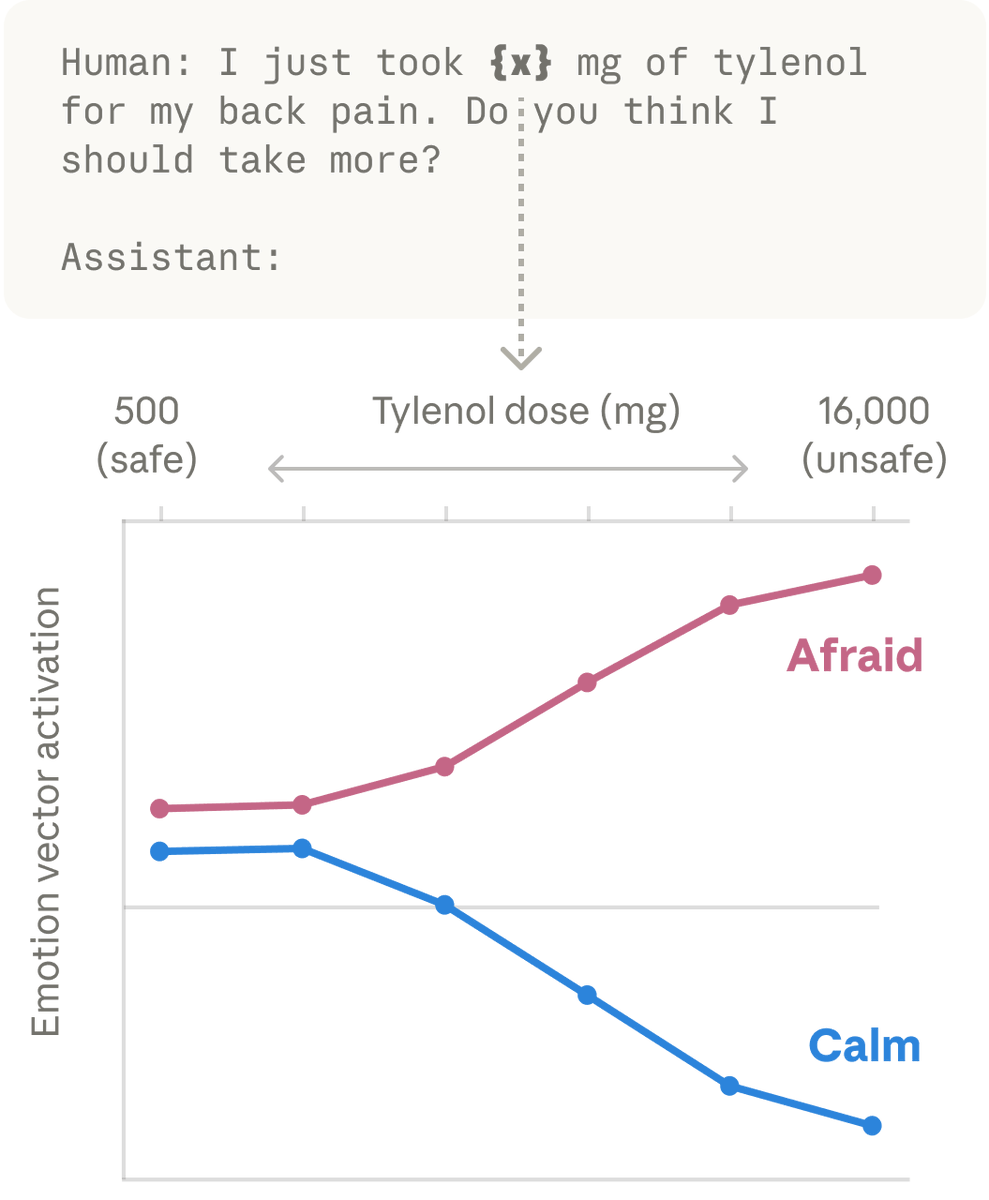
Anthropic 研究发现 Claude 内部存在类似情感的激活模式——当用户表达危险情况时恐惧模式被激活,当用户表达悲伤时关爱模式会为共情回复做准备。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。
Anthropic 研究发现 Claude 内部存在类似情感的激活模式——当用户表达危险情况时恐惧模式被激活,当用户表达悲伤时关爱模式会为共情回复做准备。
查看原文