Cursor:在 Blackwell GPU 上重建 MoE 推理引擎,速度提升 1.84 倍
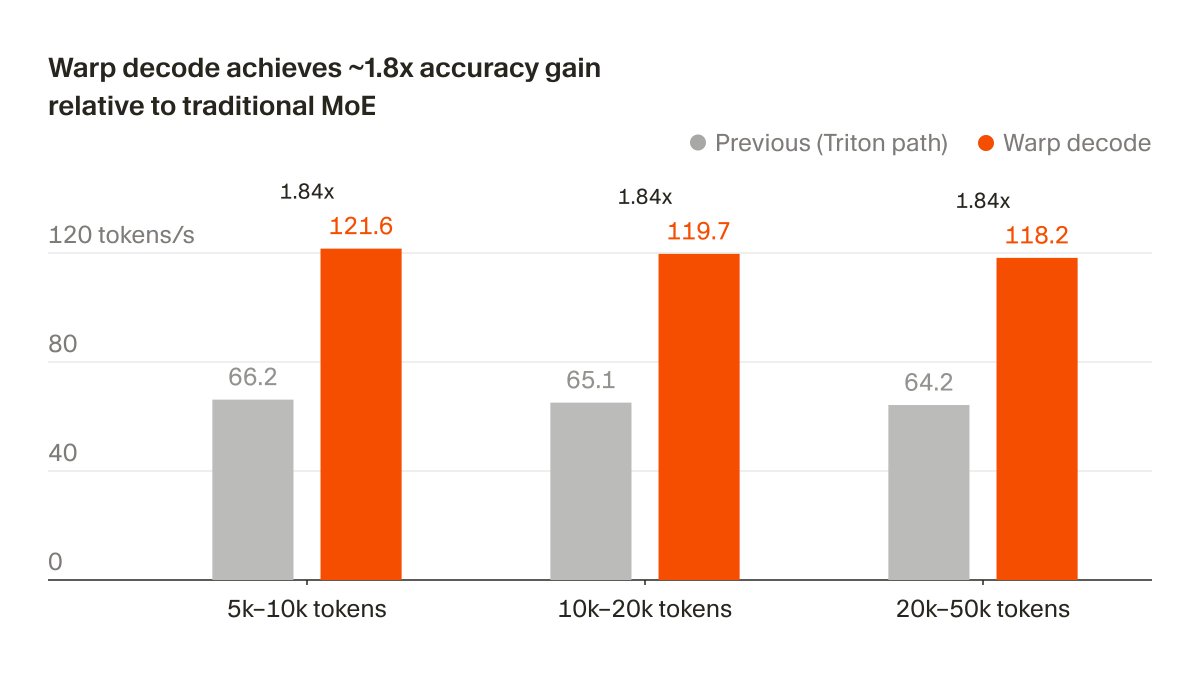
Cursor 团队重新设计了 MoE 模型在 Blackwell GPU 上的 token 生成方式,推理速度提升 1.84 倍且输出更精准。这些改进直接服务于 Composer 模型的训练迭代。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。
Cursor 团队重新设计了 MoE 模型在 Blackwell GPU 上的 token 生成方式,推理速度提升 1.84 倍且输出更精准。这些改进直接服务于 Composer 模型的训练迭代。
查看原文