Claude Mythos Preview 跑分断崖式领先,SWE-bench 93.9%、USAMO 97.6%
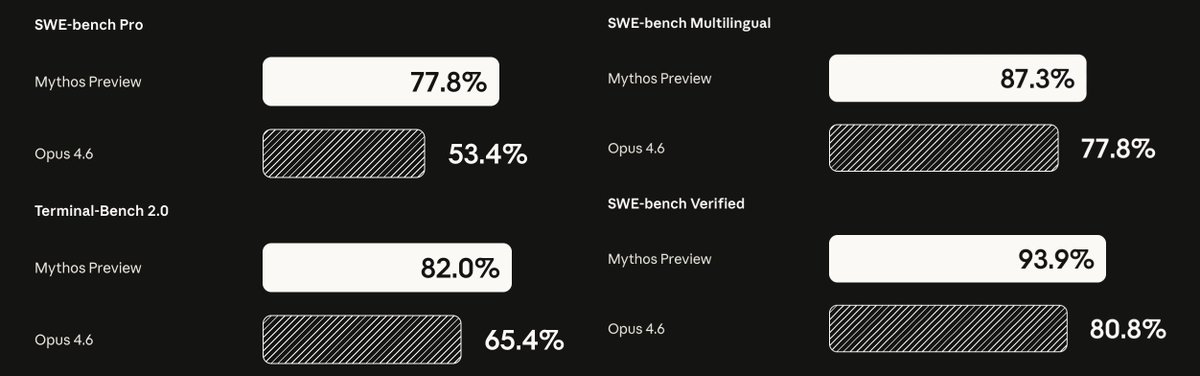
Anthropic 发布 Claude Mythos Preview 并宣布 Project Glasswing。对比 Opus 4.6,SWE-bench 从 80.8% 升至 93.9%,USAMO 从 42.3% 飙至 97.6%,在几乎所有基准上以两位数优势领先 GPT-5.4 和 Gemini 3.1 Pro。
查看原文TL;DR · 产品解读
Claude Mythos Preview 发布,SWE-bench 93.9%(+13.1pp)、USAMo 97.6%(+55.3pp),断崖式领先 GPT-5.4 和 Gemini 3.1 Pro。Anthropic 同时预告 Project Glasswing,标志着 Claude 在编程与数学推理上全面突破。
深度解读
产品是什么
Claude Mythos Preview 是 Anthropic 最新发布的旗舰推理模型系列,重点强化了代码生成(Software Engineering)和数学推理(USAMO)两大高价值场景。相比前代 Opus 4.6,在几乎所有主流基准上实现了两位数百分点的提升。
核心提升数字
- SWE-bench(软件工程基准):80.8% → 93.9%(+13.1pp)
- USAMO(美国奥数竞赛题):42.3% → 97.6%(+55.3pp)——这是最夸张的单项涨幅
对比同类竞品
- vs GPT-5.4:Claude 在 SWE-bench 和 USAMO 上均保持两位数领先,但 GPT-5.4 在某些创意写作和长上下文理解上仍有微弱优势。
- vs Gemini 3.1 Pro:Gemini 3.1 Pro 定价更低(~$0.9/M tokens vs Claude ~$15/M),但在代码和数学基准上落后约 15-20pp,适合预算敏
● 未登录访客SMARTFLOW PRO
继续阅读深度解读 + 编辑加注
下方还有 3-5 段深度分析 + Vincent 编辑加注 + 可点击信源,仅 Pro 会员可见
加入机智流 PRO →¥99 / 季 · 每周 1 篇深度研报 · 飞书+微信群双通道
已是 Pro 但仍被提示?联系反馈
参考来源
- dotey 发布推文 · 2026-04-07
本解读由 AI 自动生成 · 模板:产品解读 · 仅供参考,请以原文为准。