Meta AI:详解 Muse Spark 在预训练、强化学习和推理时的 Scaling 特性
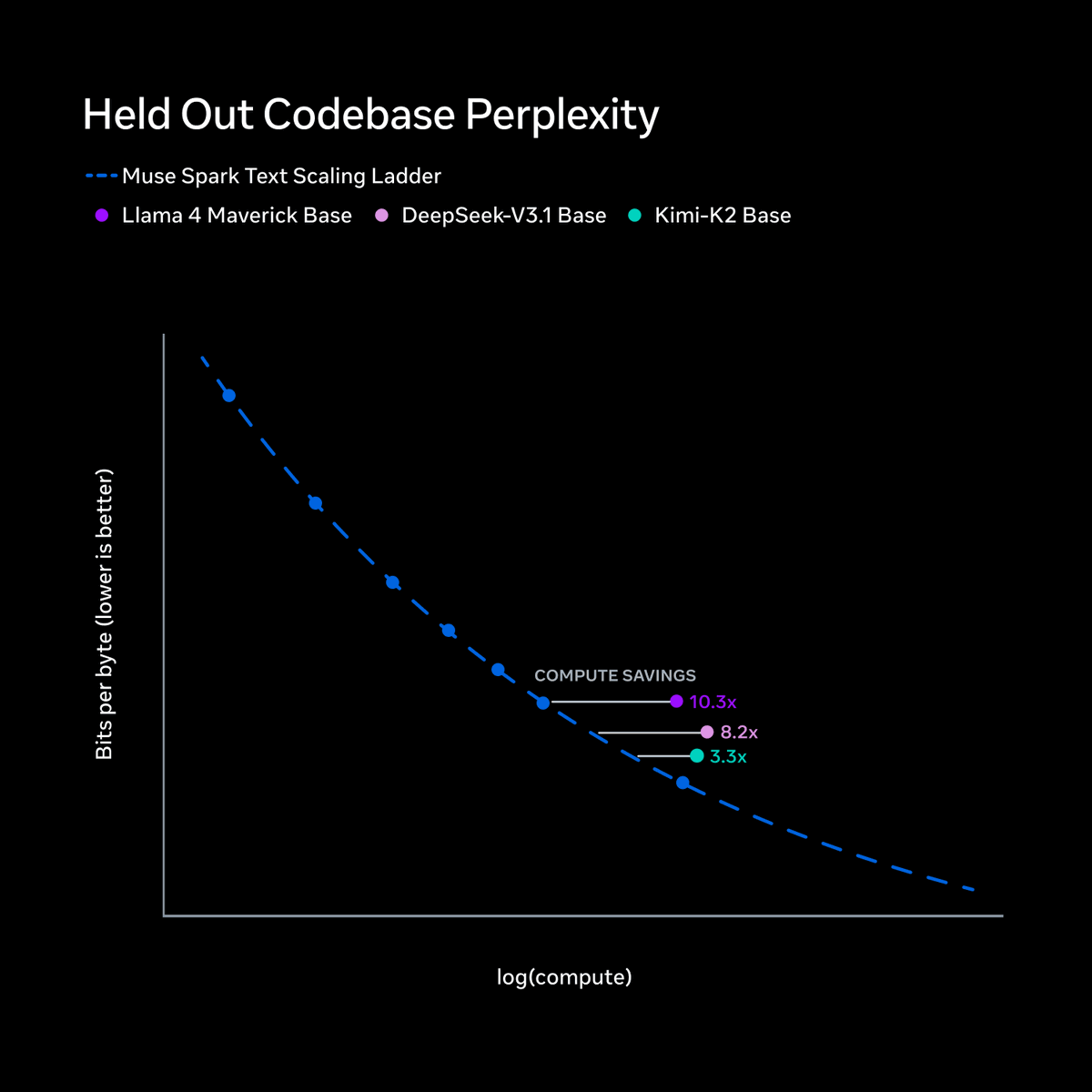
Meta 分享 Muse Spark 在三个维度的扩展研究:过去 9 个月重建预训练技术栈,提升了每单位计算量的能力提取效率。
查看原文TL;DR · 评测解读
Meta 分享 Muse Spark 在预训练、RL 和推理三阶段的 scaling 研究,声称效率提升但未披露具体指标,透明度有限。
深度解读
这是测什么?
Meta 这篇分享本质上是 scaling laws 研究——衡量模型能力如何随计算量(FLOPs)、参数规模、训练数据量增长而提升。区别于传统 benchmark 的固定任务评分,scaling 研究关注的是效率曲线:单位计算投入能换取多少能力增长。
Meta 声称在三个维度做了系统性实验:
- 预训练阶段:重新设计技术栈,提升每 FLOPs 的能力提取
- 强化学习阶段:RL 训练的 scaling 特性
- 推理阶段:推理时的 scaling 行为
方法论质疑
这份分享有几个明显的透明度问题:
- 无具体数字:全文没有披露任何 FLOPs、参数规模、能力提升百分比。"9 个月重建技术栈"是叙事而非数据。
- 无 baseline 对比:改进是相对什么的?是相对 Llama 4?相对业界 SOTA?无从判断。
- 无统计显著性说明
● 未登录访客SMARTFLOW PRO
继续阅读深度解读 + 编辑加注
下方还有 3-5 段深度分析 + Vincent 编辑加注 + 可点击信源,仅 Pro 会员可见
加入机智流 PRO →¥99 / 季 · 每周 1 篇深度研报 · 飞书+微信群双通道
已是 Pro 但仍被提示?联系反馈
参考来源
- Meta AI:详解 Muse Spark 在预训练、强化学习和推理时的 Scaling 特性 · 2026-04-08
- Chinchilla: Training Compute-Optimal Large Language Models · 2022-03-29
- Scaling Laws for Neural Language Models · 2020-01-23
本解读由 AI 自动生成 · 模板:评测解读 · 仅供参考,请以原文为准。