Anthropic:Claude 平台推出 Advisor 策略,Opus 做顾问大幅降低 Agent 成本
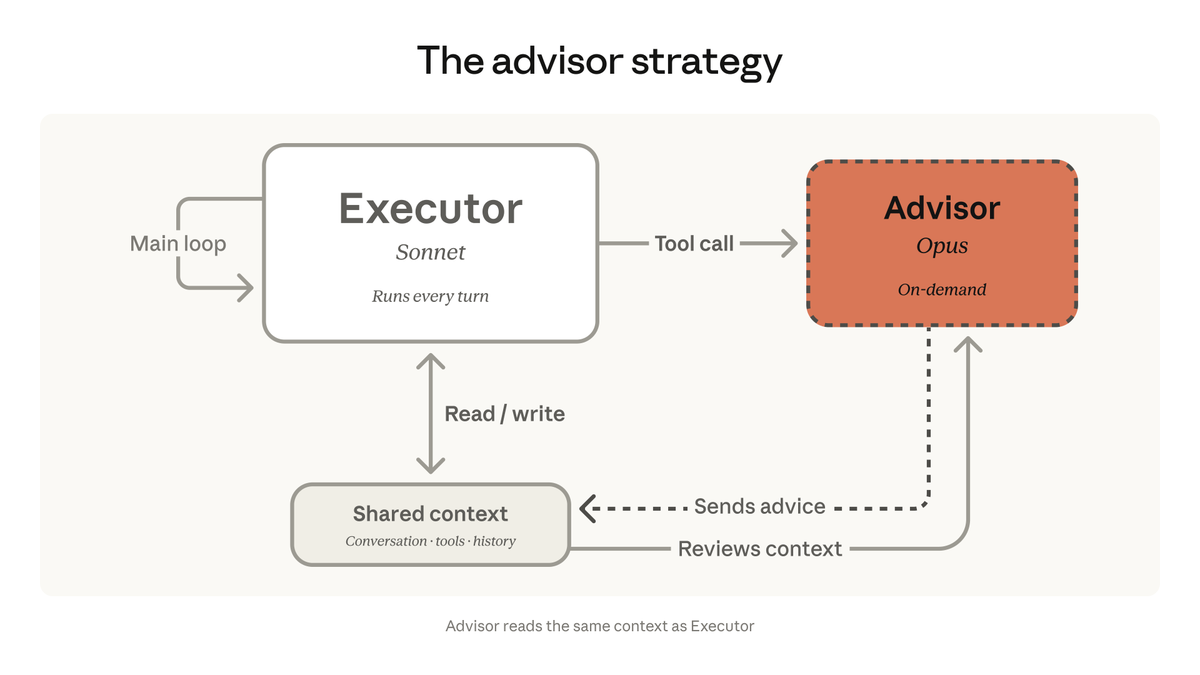
Anthropic 将 Advisor 策略引入 Claude Platform:以 Opus 作为顾问、Sonnet 或 Haiku 作为执行者,在 SWE-bench Multilingual 上比单独 Sonnet 高 2.7 个百分点,同时每任务成本降低 11.9%。开发者只需在 Messages API 中添加 advisor 工具即可启用。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。