JavaScript 已关闭 · 内容可正常浏览,但 PWA 安装 / 返回顶部 / 移动底部导航等增强功能不可用
AI
AI Insight
← 返回资讯
首页
>
资讯
> 解读
行业
@a16z
2026-04-10
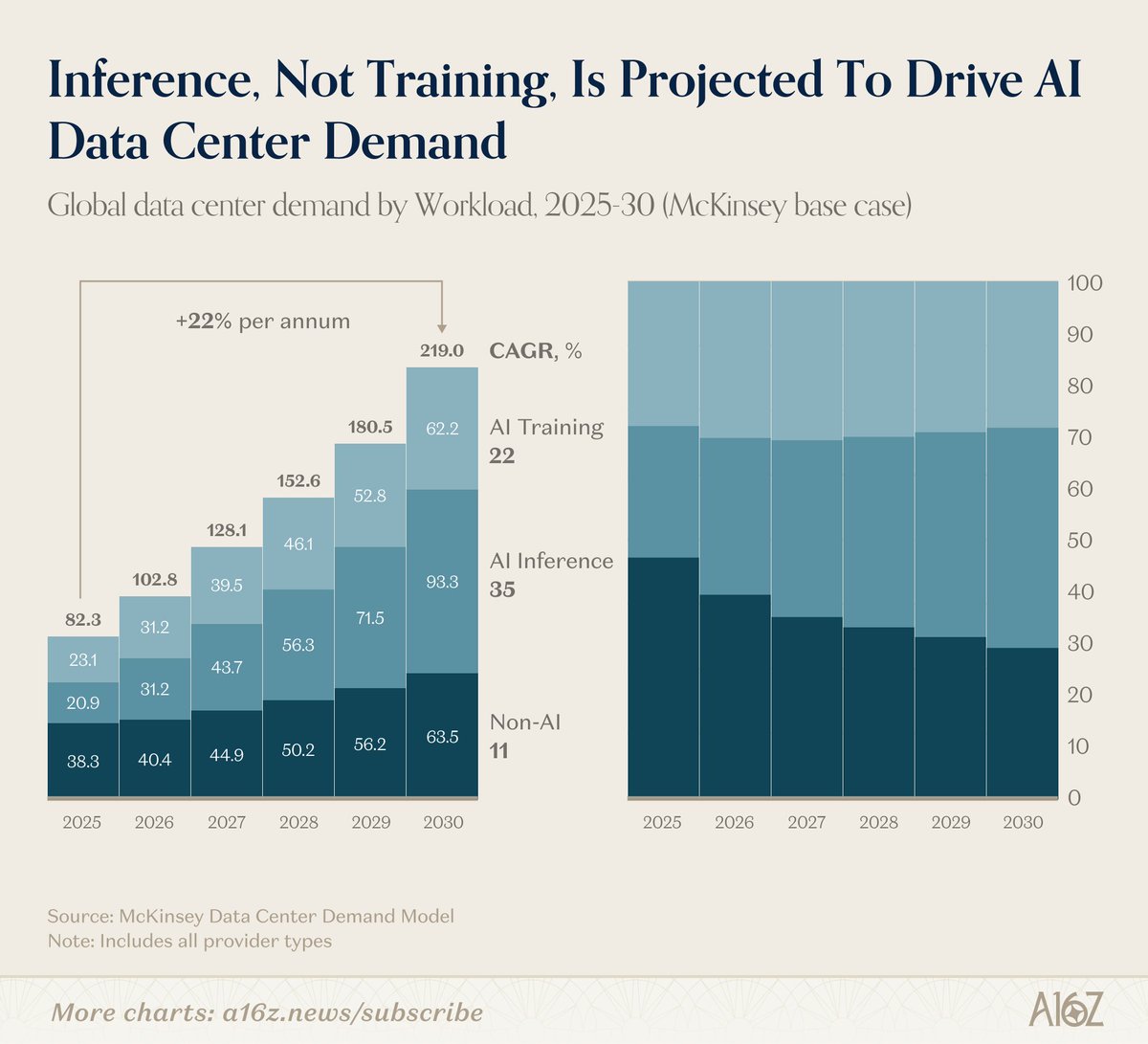
a16z:推理而非训练将成为数据中心扩建的主要驱动力
据 a16z 最新数据图表,AI 推理需求预计将取代训练,成为未来数据中心建设扩张的主要推动力。
查看原文
本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。
📑 延伸阅读 · 深度研报
产品观察 · 2026.06.18
Pro
微信「AI 专属卡」深扒:让 Agent 碰你钱包的那道安全锁
产品观察 · 2026.06.17
Pro
Cursor 版「GitHub」来了:深扒 Cursor Origin,与绕不开的 600 亿收购
产品观察 · 2026.06.17
Pro
智谱 GLM-5.2 深扒:1M 可用上下文、MIT 开源,与「开放」这步棋
想读得更深?AI Insight Pro 解锁全部深度研报与资讯完整解读。
了解 Pro →
首页
资讯
研报
访谈
我的