LMSys 发布 HiSparse:分层内存加速稀疏注意力,吞吐量提升 3-5 倍
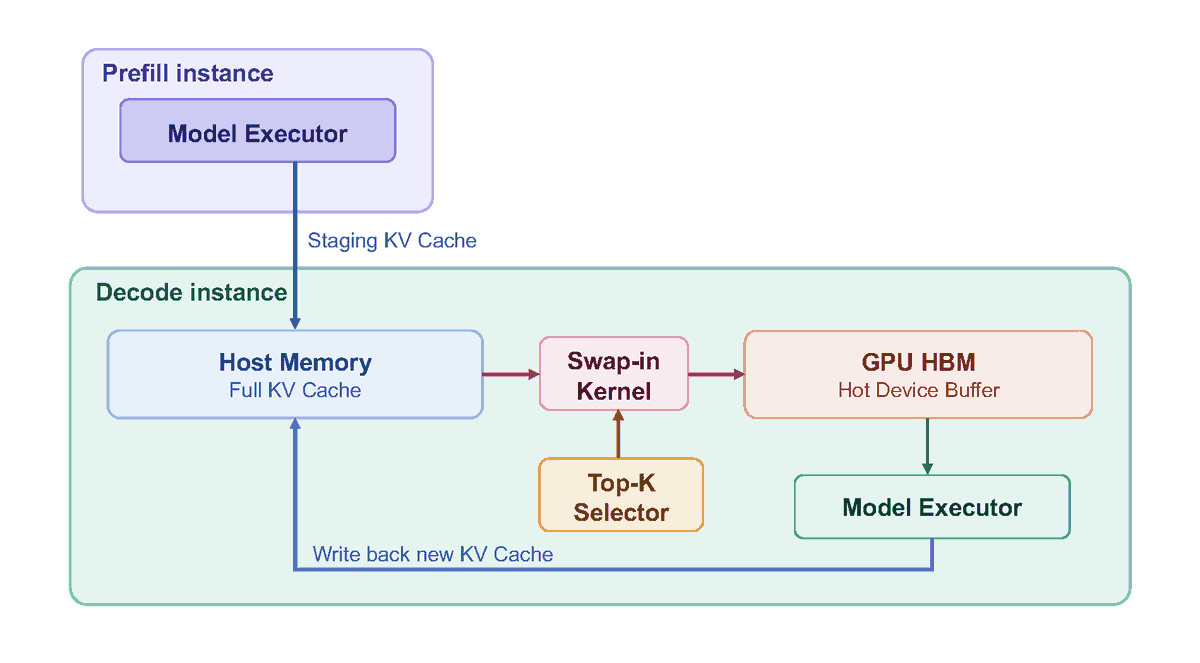
HiSparse 通过将不活跃 KV Cache 主动卸载到主机内存解决容量瓶颈,在 8xH200 上 256 并发请求下实现 3 倍吞吐提升,长上下文场景可达 5 倍。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。
HiSparse 通过将不活跃 KV Cache 主动卸载到主机内存解决容量瓶颈,在 8xH200 上 256 并发请求下实现 3 倍吞吐提升,长上下文场景可达 5 倍。
查看原文