Cursor Agent 3.0 被曝内置 Claude Code 框架,官方称系小范围 A/B 测试
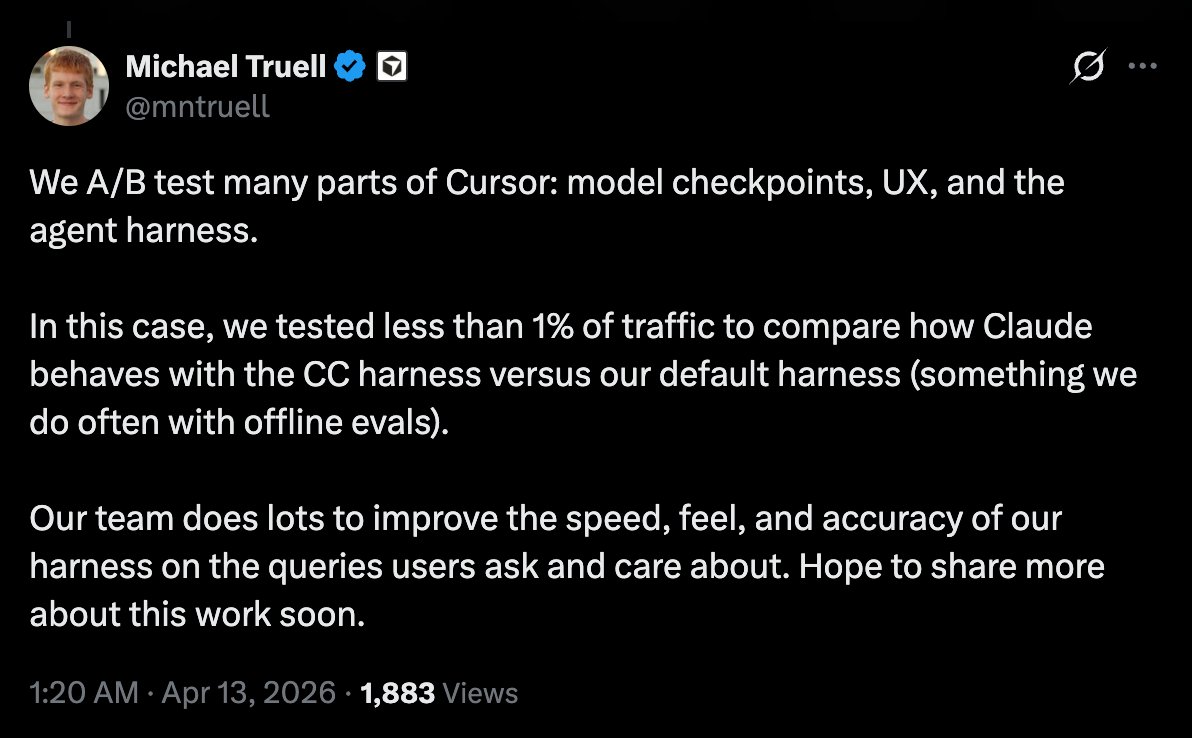
开发者逆向发现 Cursor 3.0 内置 Anthropic Agent 框架并替换品牌标识,Cursor 联合创始人回应称仅为覆盖不到 1% 流量的性能对比测试。
查看原文产品具体是什么
Cursor 是一款基于 VS Code 的 AI 代码编辑器,通过深度集成大模型实现代码补全、对话生成和 Agent 自动编程等功能。Claude Code 则是 Anthropic 推出的官方 Agent 框架,支持模型通过命令行与环境交互、执行代码修改等任务。本次争议的焦点在于:逆向工程师发现 Cursor 3.0 内部集成了 Claude Code 的核心逻辑模块,但将原始品牌标识替换为了 Cursor 自有品牌标识。
官方回应可信度分析
Cursor 联合创始人 Alex 回应称该行为是「覆盖不到 1% 流量的性能对比测试」。从工程实践看,这种解释有几种可能的合理性:其一,Cursor 确实在评估 Claude Code 的决策逻辑与自己实现的差异;其二,在内部做跨模型基准测试时,确实可能借用竞品的 pipeline 做对照。然而,替换品牌标识这一操作本身很难用「技术测试」解释——正规的性能对比应在独立环境运行,无需替换 logo 或字符串。从这个角度看,开发者社区的质疑并非无据。
对 Cursor 意味着什么
Cursor 成立于 2021 年,靠「第一个真正面向 Agent 场景的代码编辑器」叙事迅速崛起,估值已超 10 亿美元。其核心竞争力
继续阅读深度解读 + 编辑加注
下方还有 3-5 段深度分析 + Vincent 编辑加注 + 可点击信源,仅 Pro 会员可见
¥99 / 季 · 每周 1 篇深度研报 · 飞书+微信群双通道
已是 Pro 但仍被提示?联系反馈