Perplexity:搜索增强回答后训练新研究,Qwen 事实性匹配 GPT
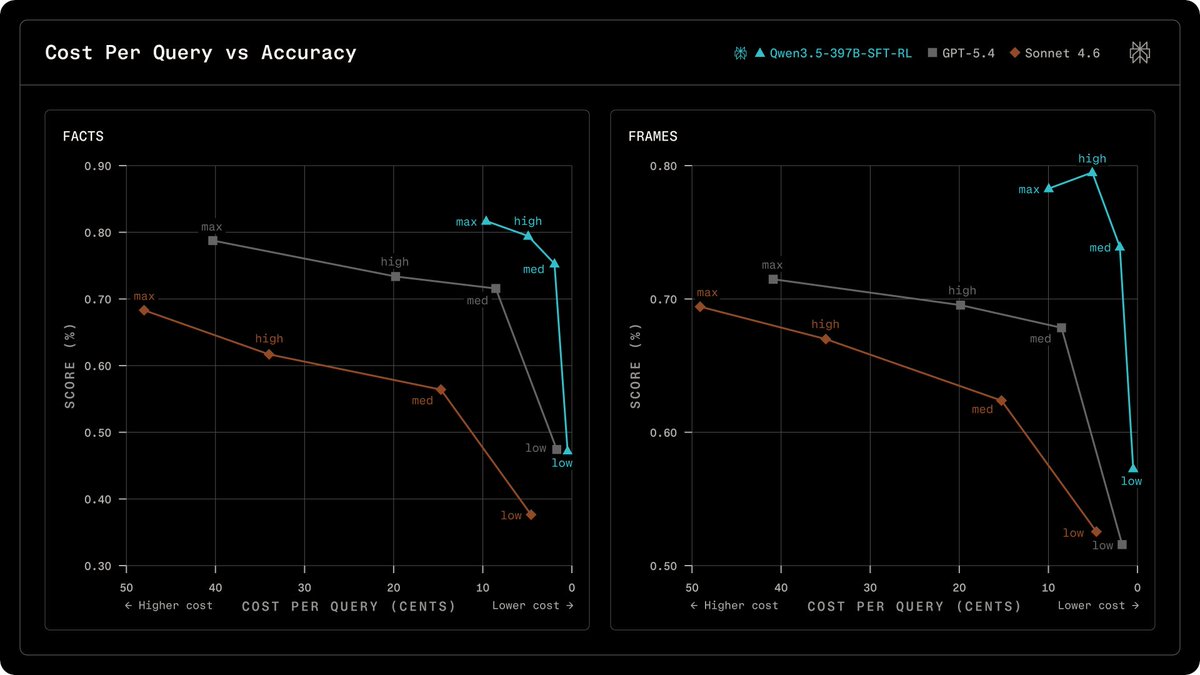
Perplexity 发布搜索增强回答的后训练研究,采用 SFT + RL 管线提升搜索、引用质量、指令跟随与效率,搭配 Qwen 模型在事实性上以更低成本匹配或超越 GPT 模型。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。
Perplexity 发布搜索增强回答的后训练研究,采用 SFT + RL 管线提升搜索、引用质量、指令跟随与效率,搭配 Qwen 模型在事实性上以更低成本匹配或超越 GPT 模型。
查看原文