OpenAI:GPT-5.5 每 token 延迟追平 5.4,Codex 任务更省 token
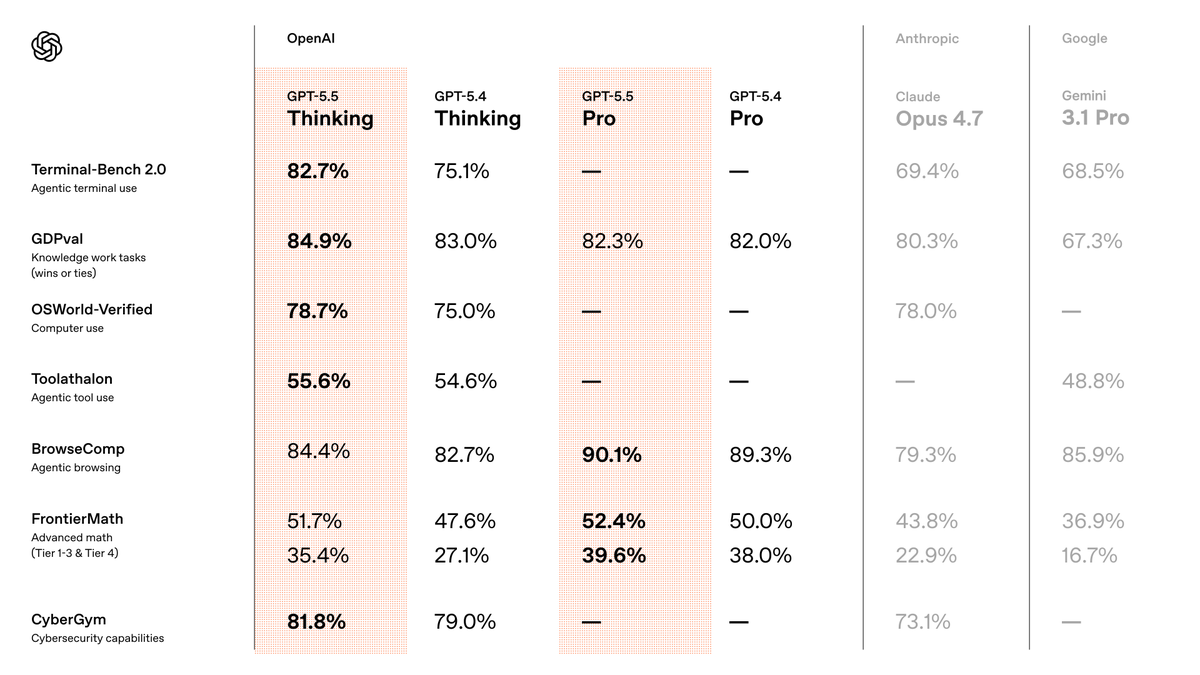
OpenAI 表示 GPT-5.5 在真实部署中保持与 GPT-5.4 相同的 per-token 延迟,但在几乎所有评测中表现更好,并在 Codex 任务中使用明显更少的 token。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。
OpenAI 表示 GPT-5.5 在真实部署中保持与 GPT-5.4 相同的 per-token 延迟,但在几乎所有评测中表现更好,并在 Codex 任务中使用明显更少的 token。
查看原文