DeepSeek-V4-Pro:Agent 编码开源 SOTA,世界知识仅次于 Gemini-3.1-Pro
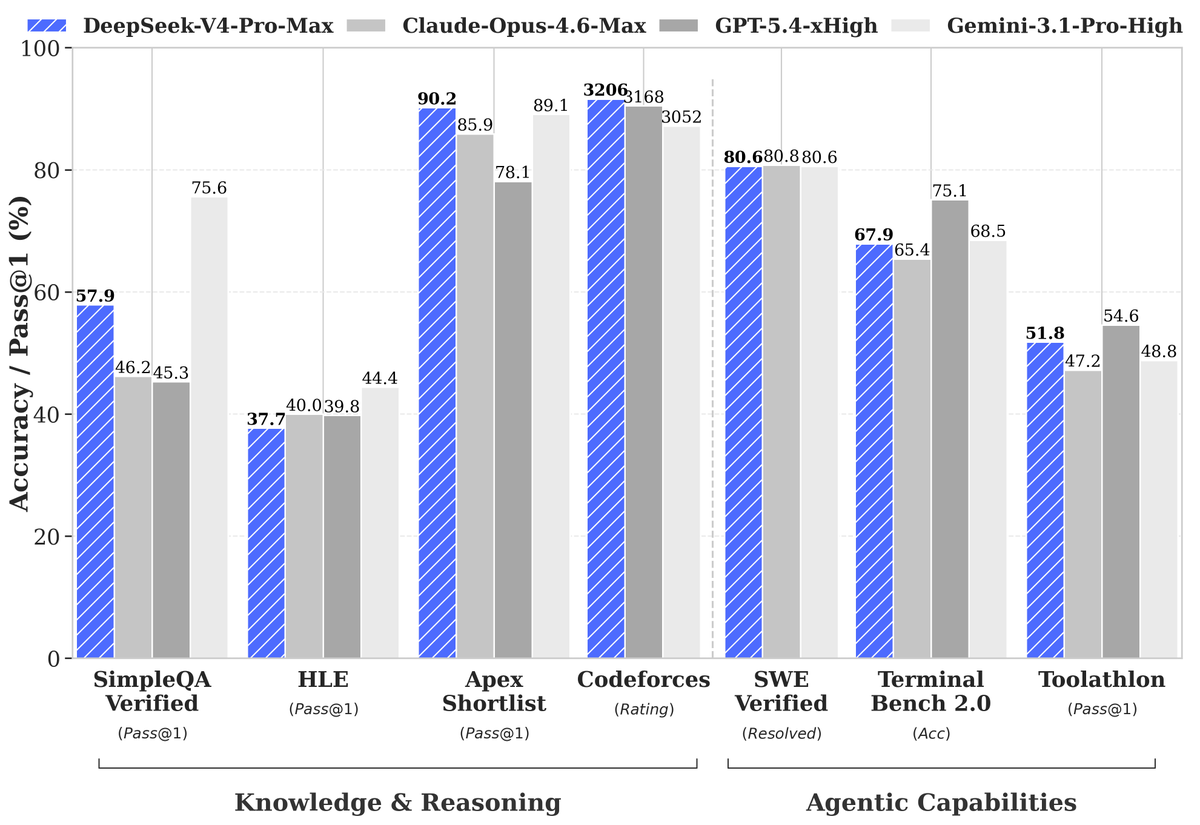
V4-Pro 在 Agentic Coding 基准达开源 SOTA,世界知识领先全部开源模型仅次 Gemini-3.1-Pro,数学/STEM/编程推理能力对标顶尖闭源模型。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。
V4-Pro 在 Agentic Coding 基准达开源 SOTA,世界知识领先全部开源模型仅次 Gemini-3.1-Pro,数学/STEM/编程推理能力对标顶尖闭源模型。
查看原文