DeepSeek:V4 引入 DSA 稀疏注意力,1M 上下文成官方默认
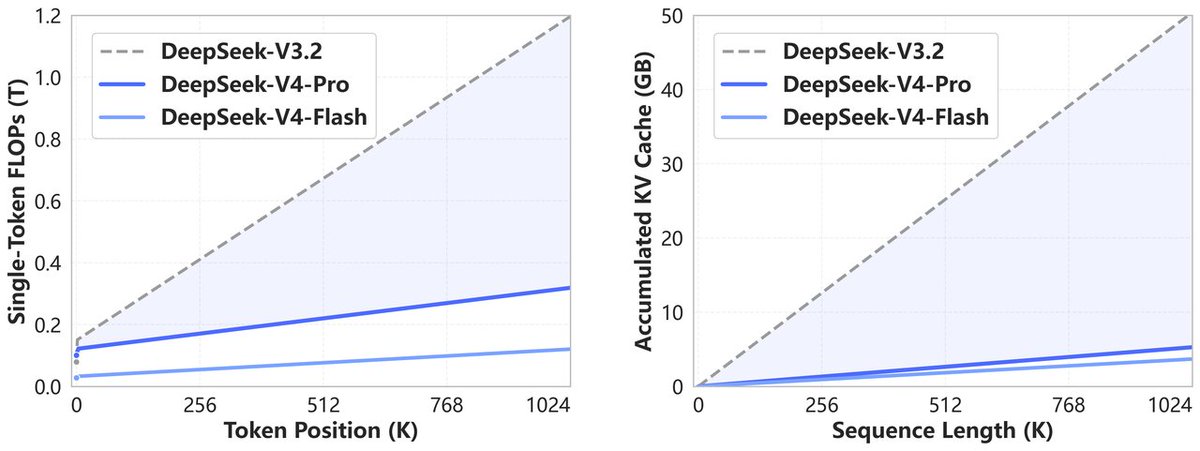
DeepSeek-V4 采用 token-wise 压缩与新型稀疏注意力 DSA(DeepSeek Sparse Attention),在大幅降低算力与显存开销的同时,所有官方服务默认支持 1M 超长上下文。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。
DeepSeek-V4 采用 token-wise 压缩与新型稀疏注意力 DSA(DeepSeek Sparse Attention),在大幅降低算力与显存开销的同时,所有官方服务默认支持 1M 超长上下文。
查看原文