vLLM:Day-0 支持英伟达 Nemotron 3 Nano Omni 多模态混合 MoE 模型
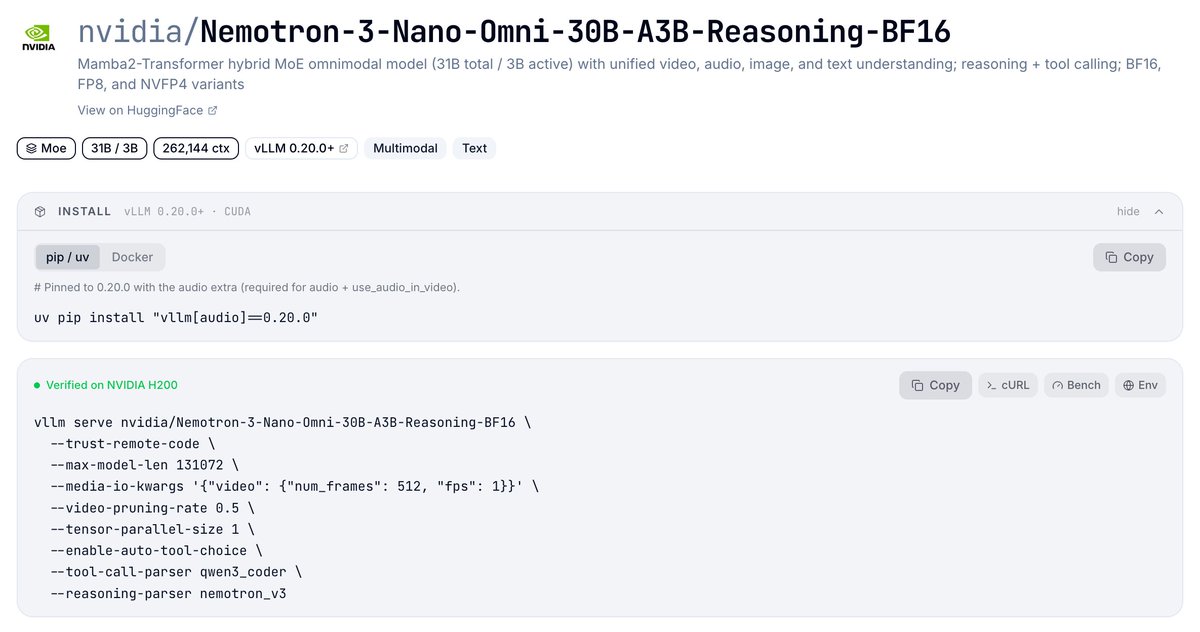
vLLM 宣布对 NVIDIA Nemotron 3 Nano Omni 提供 Day-0 支持。该模型为 30B 参数 Transformer-Mamba 混合 MoE(3B 激活),统一视觉/音频/视频/文本,256K 上下文,支持 FP8 与 NVFP4 量化。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。