vLLM:Day-0 支持蚂蚁 Ling-2.6-flash MoE 模型
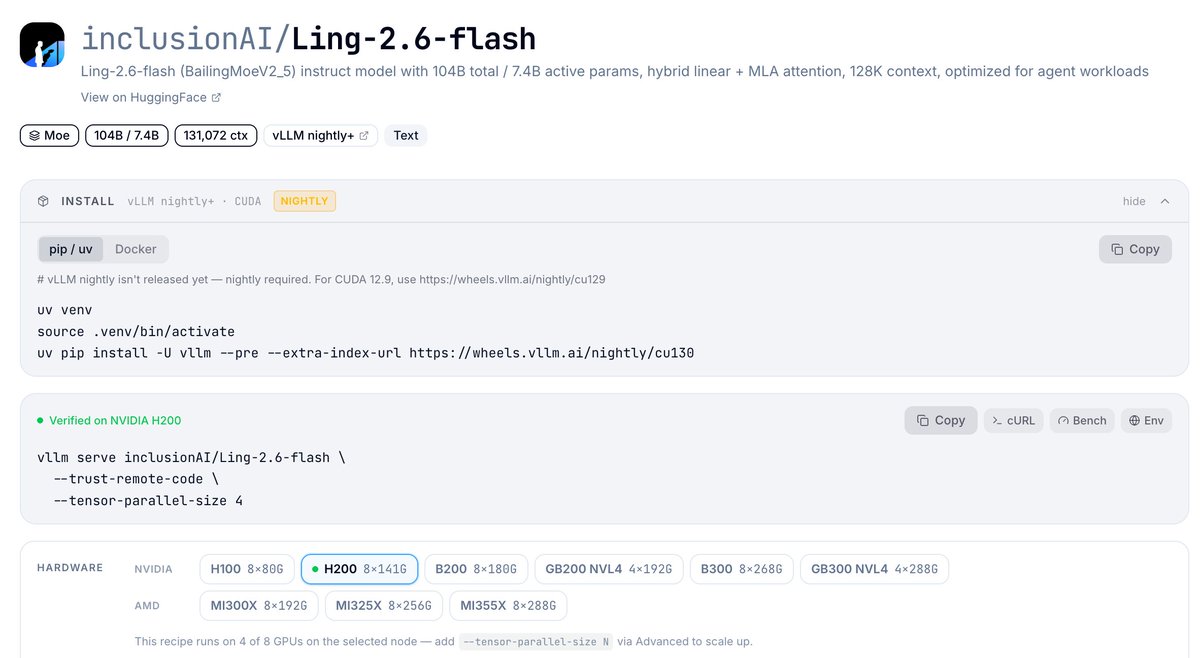
蚂蚁集团 Ling-2.6-flash 即时 MoE 模型上线即获 vLLM Day-0 支持。104B 总参/7.4B 激活,混合 1:7 MLA+Lightning Linear 注意力,262K 上下文,原生工具调用。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。
蚂蚁集团 Ling-2.6-flash 即时 MoE 模型上线即获 vLLM Day-0 支持。104B 总参/7.4B 激活,混合 1:7 MLA+Lightning Linear 注意力,262K 上下文,原生工具调用。
查看原文