vLLM 发布原生权重同步 API 等两项 RL 强化升级,将推理引擎能力延伸至训练环节,标准化分布式 RL 场景下的权重传输,降低自研 Agent 训练门槛。
产品是什么
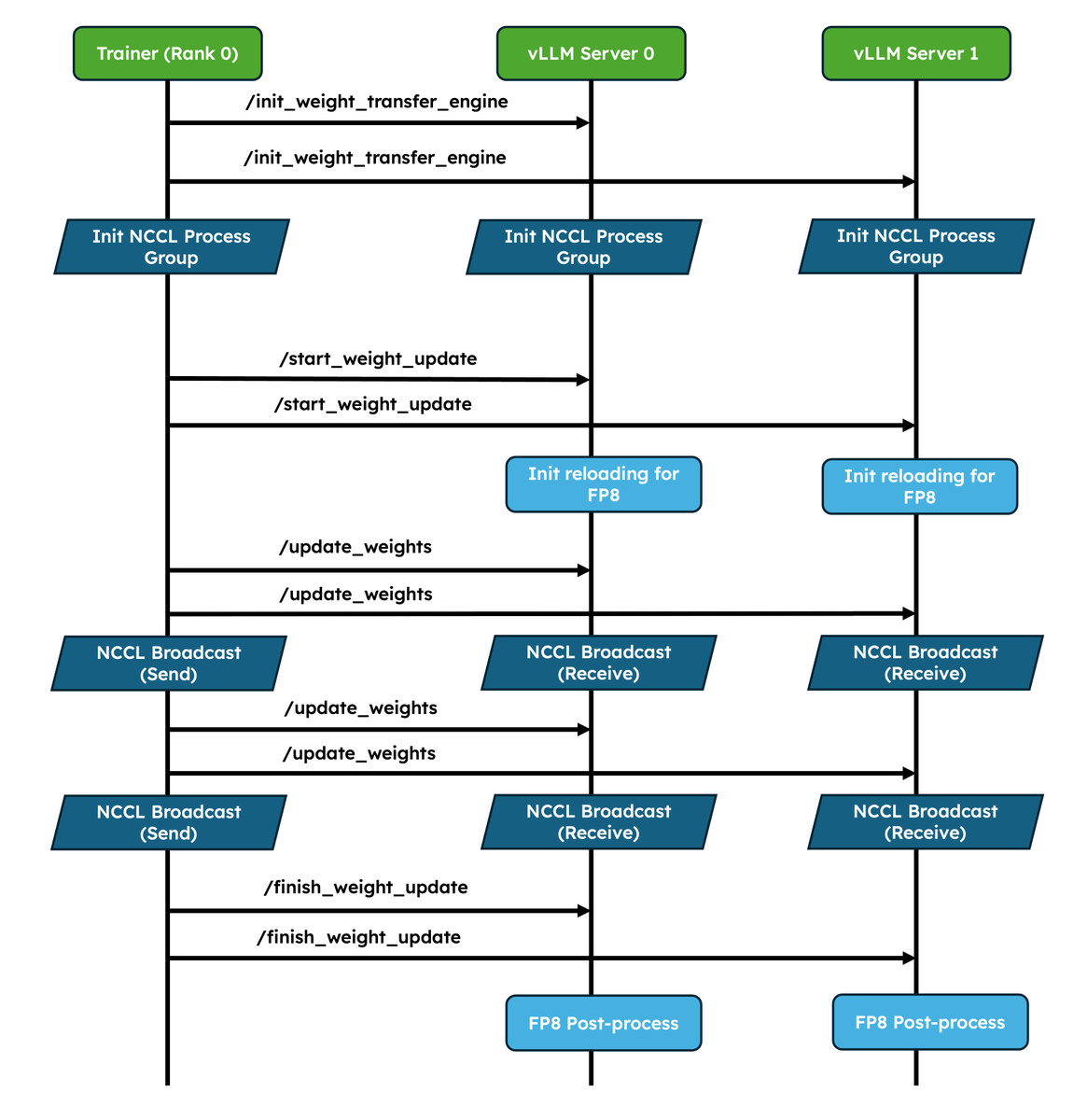
vLLM 团队在 X(Twitter)上预告了两项针对强化学习(RL)训练的重大升级,核心是原生权重同步 API(Native Weight Synchronization API)——一套标准化的权重传输接口。这意味着 vLLM 不再只是推理引擎,正在向训练侧延伸,成为 RL 流程中的权重读写中枢。
解决什么问题
当前分布式 RL 训练(例如 PPO、GRPO)存在一个痛点:actor 和 critic 模型分布在多 GPU/Nodes 时,权重同步依赖开发者自行实现的 torch.distributed 或自定义脚本,稳定性和效率参差不齐。vLLM 的原生 API 相当于提供了一套开箱即用的高性能权重广播/聚合管道,减少定制粘合代码,降低通信瓶颈。
相比之前版本的变化
vLLM 0.8.x 系列已支持 speculative decoding、prefix caching 等推理优化,本次升级是从推理引擎向训练支撑工具的战略延伸。API 若落地,将使 vLLM 同时覆盖 RL 的rollout(采样推理)和weight sync两个高开
继续阅读深度解读 + 编辑加注
下方还有 3-5 段深度分析 + Vincent 编辑加注 + 可点击信源,仅 Pro 会员可见
¥99 / 季 · 每周 1 篇深度研报 · 飞书+微信群双通道
已是 Pro 但仍被提示?联系反馈
- vLLM 发布两项强化学习重大升级(X 原文) · 2026-05-29
- vLLM GitHub 主页 · 2025-01-01
- vLLM 官方文档 · 2025-01-01