TL;DR · 评测解读
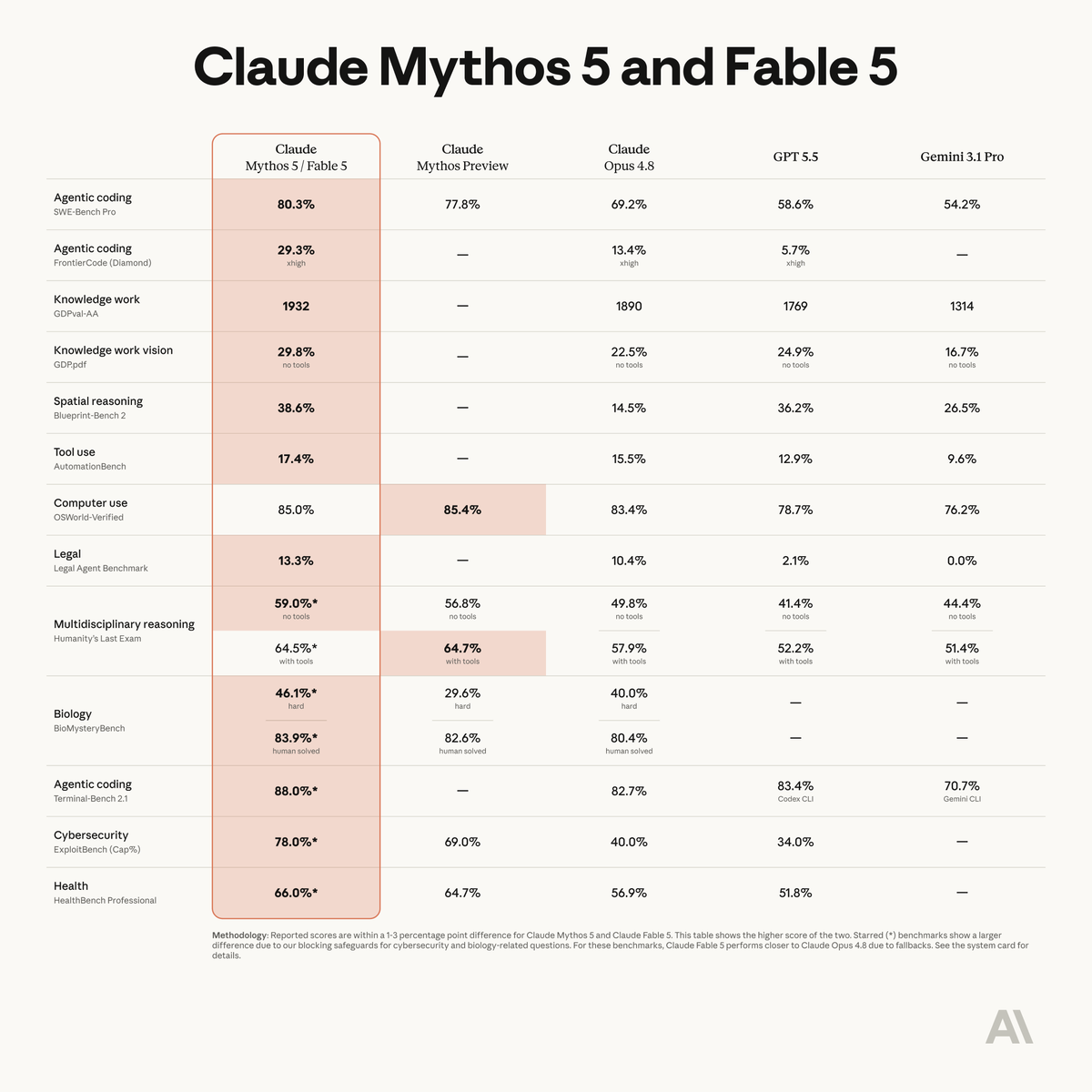
Fable 5在多个主流基准上全面领先,尤其在复杂任务上优势显著。跑分虽好看,但Benchmark ≠ 实际工作流表现——复杂任务优势能否转化为真实开发效率,仍需实践验证。
深度解读
测什么?
Fable 5基准测试覆盖四大场景:软件工程(SWE-bench类任务)、知识工作、科研和视觉任务。这些benchmark基本覆盖了当前Agent落地最核心的场景。任务越复杂、链条越长,Fable 5领先幅度越大——这暗示其推理深度和上下文管理能力可能有架构级提升,而非单纯的刷题式优化。
方法论质疑
必须指出几个问题:
- contamination风险:如果Fable训练数据截取时间晚于Benchmark发布,模型"见过"测试集的可能性无法排除。SWE-bench已有多次"刷分"争议。
- 任务复杂度≠真实场景复杂度:Benchmark任务有标准答案,真实开发是模糊的、迭代的、需多轮沟通的。
- 视觉基准的局限:视觉benchmark(如VQA、Chart understanding)往往测试单图理解,不一定能泛化到文档理解、多图对比等实际场景。
- 领先幅度未披露
● 未登录访客SMARTFLOW PRO
继续阅读深度解读 + 编辑加注
下方还有 3-5 段深度分析 + Vincent 编辑加注 + 可点击信源,仅 Pro 会员可见
加入机智流 PRO →¥99 / 季 · 每周 1 篇深度研报 · 飞书+微信群双通道
已是 Pro 但仍被提示?联系反馈
参考来源
- Fable 5基准测试全面领先 - @claudeai · 2026-06-09
- SWE-bench: Can Language Models Resolve Real Software Bugs? · 2024-10-01
- Rethinking Language Model Benchmarking: Contamination and Reliability · 2024-06-01
本解读由 AI 自动生成 · 模板:评测解读 · 仅供参考,请以原文为准。