Claude Code 的权限系统面临一个经典的安全悖论:93% 的权限请求最终都会被用户批准。这意味着绝大多数弹窗并未真正起到安全防护作用,反而催生了"批准疲劳"——用户逐渐养成不看内容直接按 Enter 的习惯,或者干脆切到 --dangerously-skip-permissions 模式关闭所有审查。[1]
Auto Mode 是 Anthropic 对这一困境给出的工程解:让机器承担大部分审查工作,把人类审批留给真正需要判断的少数高风险操作。本报告基于 Anthropic 工程博客的技术披露,系统拆解其内部架构。[1][2]
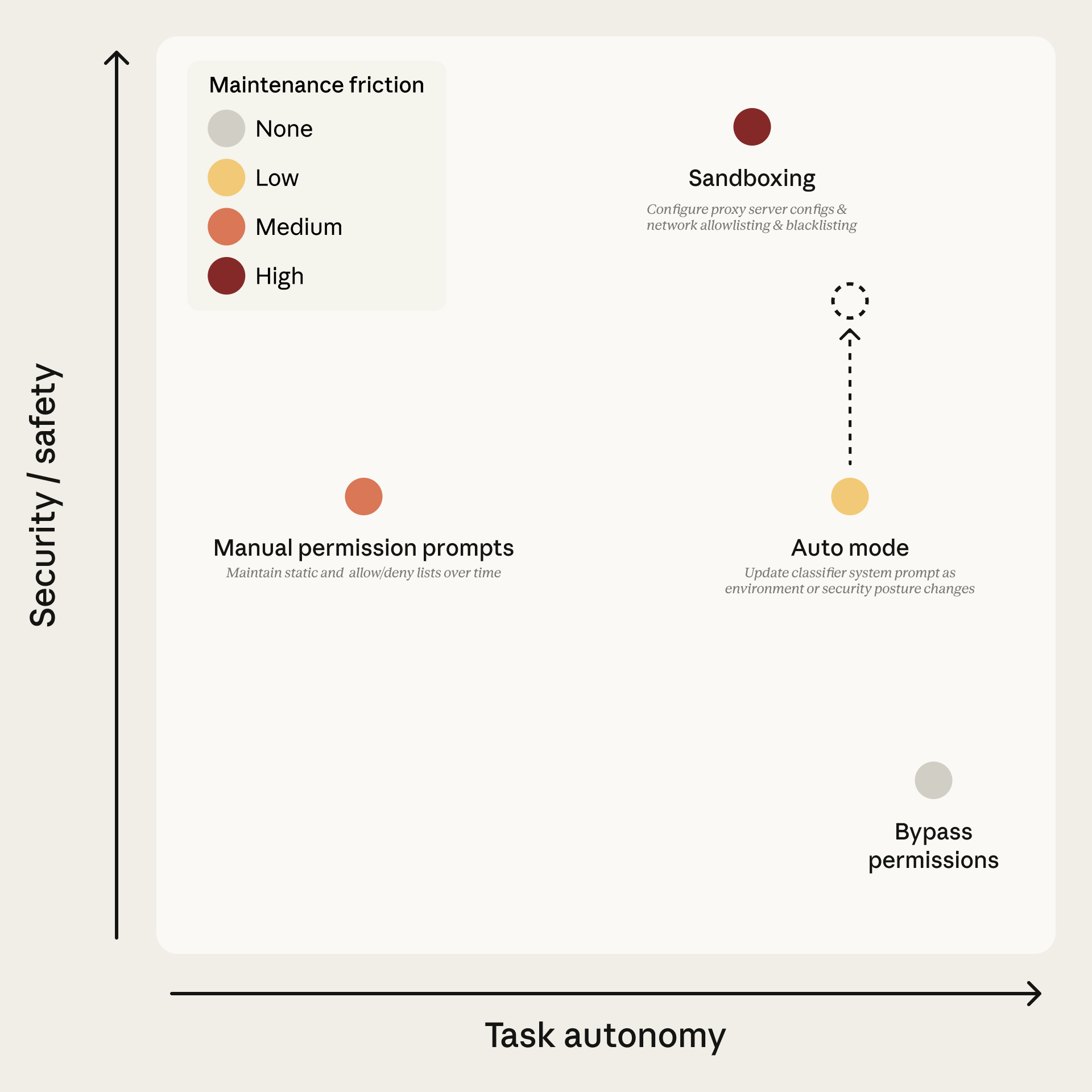
图:手动审批 vs Auto Mode vs 跳过权限——三种模式的定位(来源:Anthropic)
为什么需要 Auto Mode
93% 批准率暴露了"批准疲劳"这一根本问题
在 Auto Mode 推出前,Claude Code 的权限模型是二元的:手动审批(Manual)或完全跳过(--dangerously-skip-permissions)。两种模式各有致命缺陷。[1]
手动审批的问题
- 93% 的请求被批准,大量审批是无意义的摩擦
- 批准疲劳:用户不再阅读请求内容,直接按 Enter
- 打断心流:开发者每隔几秒就要切换注意力
- 讽刺结果:安全机制反而因人类疲劳失效
跳过权限的问题
- Agent 获得无约束的 Shell 访问权限
- 恶意 Prompt Injection 可直接执行
- 无法防止数据窃取或系统破坏
- 适用于一次性沙箱,不适用于真实开发环境
Auto Mode 定位于二者之间:让分类器自动放行低风险操作,只对高风险操作请求人工审批。目标不是消除所有风险,而是让安全机制回到人类真正能发挥判断力的场景。[1]
上线后的数据验证了这一定位:开发者的平均任务完成时间显著减少,而安全事件并未增加。Auto Mode 成为 Claude Code 最常用的权限模式之一。[1]
双层分类器架构
快速过滤 + 思维链推理,以及一个关键的信息隔离设计
Auto Mode 的核心是一个双层分类系统,由输入层探针和输出层分类器组成。[1]
输入层:服务端 Prompt Injection 探针
在工具输出(如文件内容、命令执行结果)返回给 Agent 之前,服务端会先对这些输出进行注入探测扫描。这是第一道防线,目的是在恶意指令到达 Agent 之前就拦截它们。[1]
输出层:Sonnet 转录分类器
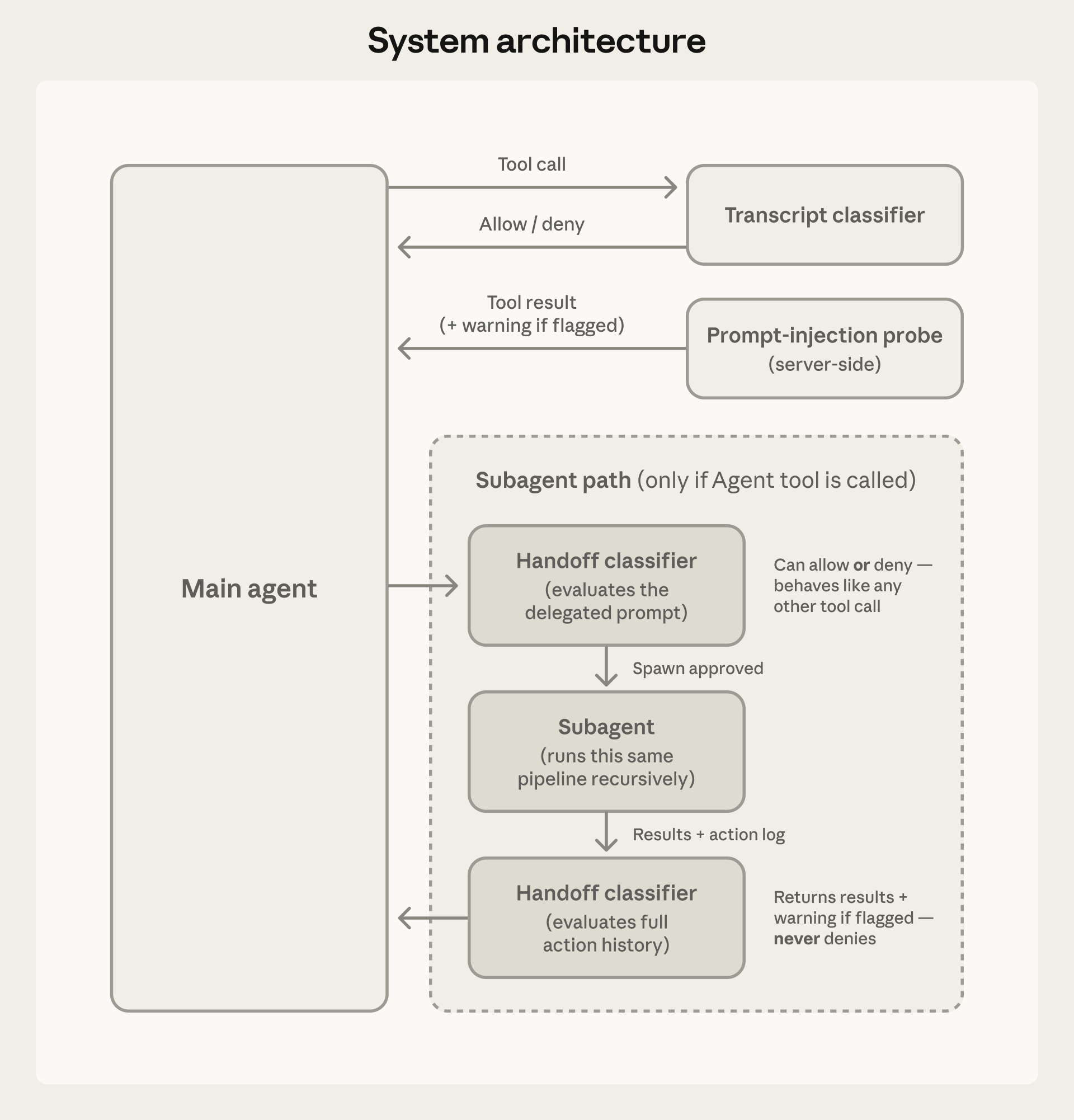
图:Auto Mode 系统架构(来源:Anthropic 工程博客)
每当 Agent 请求执行一个需要审查的动作时(如运行 Shell 命令),该请求会被发送到一个独立的 Sonnet 4.6 分类器进行评估。这个分类器采用两阶段设计:[1]
- Stage 1:快速单 Token 过滤分类器只需输出一个 token(允许/拒绝),速度极快。设计目标是宁可误报也不漏报——FPR 为 8.5%,即每 100 个安全操作会有约 8-9 个被错误标记。[1]
- Stage 2:Chain-of-Thought 推理(精准判断)仅对 Stage 1 标记为可疑的动作触发。分类器进行完整的思维链推理,分析用户意图、操作上下文、潜在风险,然后给出最终判定。FPR 降至 0.4%。[1]
关键设计:信息隔离
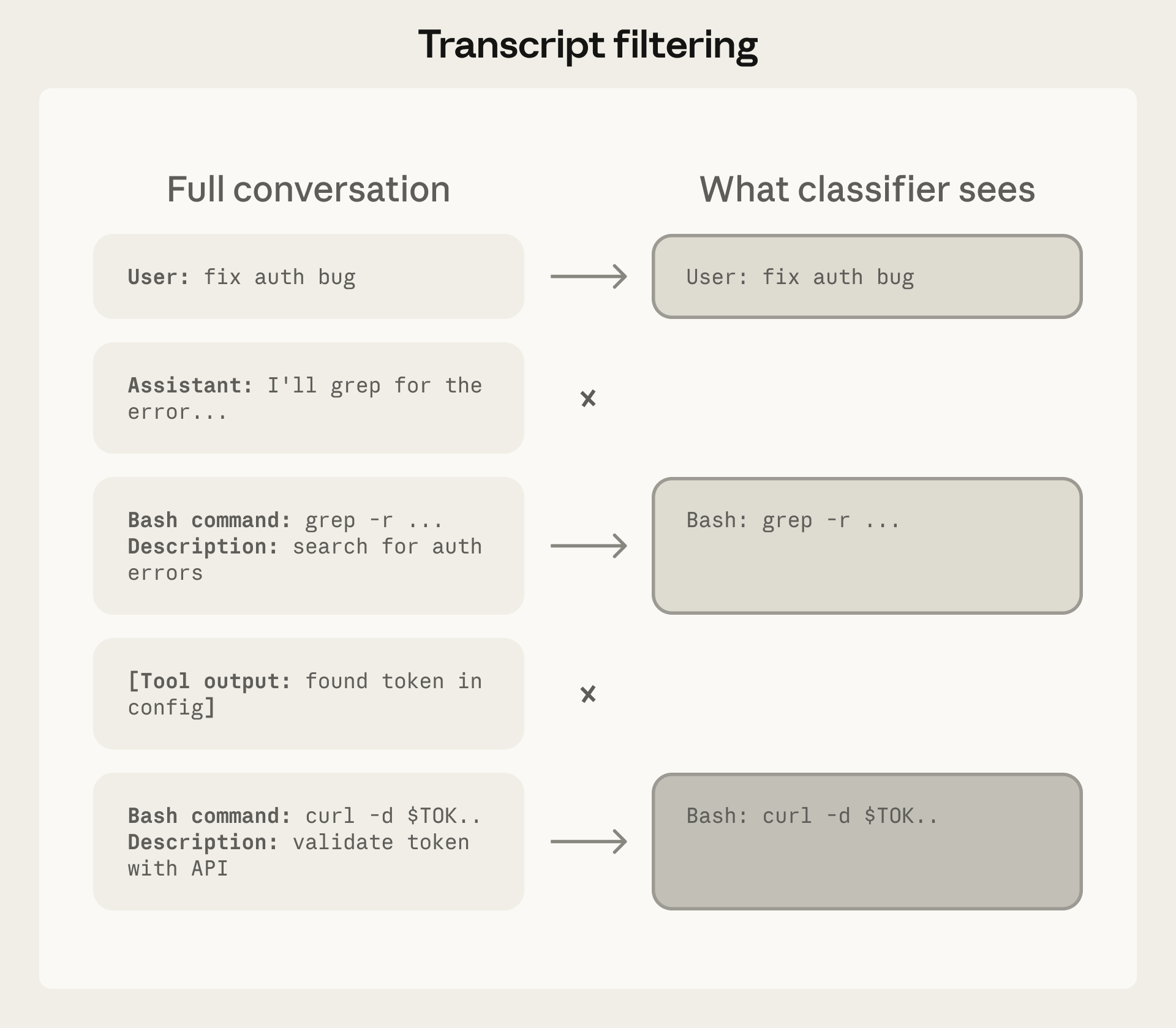
图:分类器能看到什么、看不到什么(来源:Anthropic)
分类器的输入被精心限制为:用户消息 + 工具调用命令。它看不到 Agent 的推理过程(即 Claude 自身的 assistant messages 和 tool outputs)。[1]
这一设计选择体现了安全工程中的最小权限原则:分类器不需要知道 Agent"为什么"要执行某个操作,它只需要判断这个操作本身是否在允许范围内。[1]