Claude Opus 4.7 — 什么情况下用,什么情况下别用
A One-Line Read
一把极度锋利但也极度专用的 agent 编程手术刀。
Claude Opus 4.7 在编程 agent、代码审查、细颗粒度修复等"真正干活"的场景拉开差距。但在长上下文召回、创意写作、多轮研究三个维度,能力出现明显回撤。它不再是"默认最强模型",而是"特定场景下断档领先的模型"[1][2][3]。
64.3%
SWE-bench Pro
70%
CursorBench 盲测
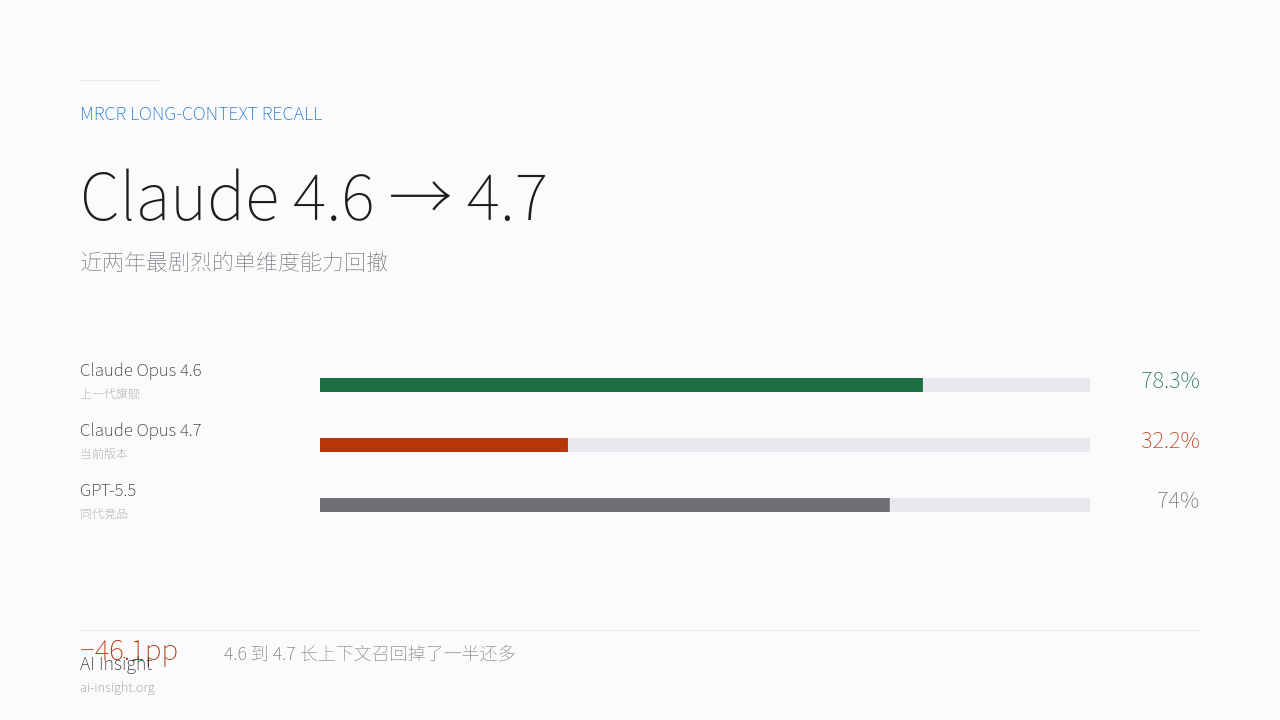
32.2%
MRCR 长上下文召回 · vs 4.6 的 78.3%
57
AA Intelligence Index
Versus 4.6
核心升级与回退一览。
| 维度 | Opus 4.6 | Opus 4.7 | 变化 |
|---|---|---|---|
| SWE-bench Pro | 59.4% | 64.3% | +4.9 |
| Terminal-Bench | 63.8% | 69.4% | +5.6 |
| CursorBench 盲测 | 62% | 70% | +8.0 |
| MRCR 长上下文召回 | 78.3% | 32.2% | −46.1 |
| 写作偏好(盲测) | 41% | 47% | +6.0 |
| 新增 · xhigh effort | — | ✓ | 推理新档位 |
| 新增 · task budgets | — | ✓ | API token 上限 |