速览目录 · Top 30 本周热榜
| # | 论文 | 领域 | 日期 | Votes | 一句话 |
|---|---|---|---|---|---|
| 1 | Utonia | 3D视觉 | 03-04 | 138 | 一个编码器统一五大点云域,跨域涌现提升机器人操作 |
| 2 | HACRL | 多智能体RL | 03-05 | 136 | 异构Agent共享验证轨迹互学习,3.3% 超越 GSPO |
| 3 | OmniLottie | 矢量动画 | 03-03 | 131 | Lottie Token自回归生成,多模态指令驱动矢量动画 |
| 4 | ADE-CoT | 图像编辑 | 03-03 | 130 | 难度感知预算分配+早期剪枝,图像编辑CoT 2倍加速 |
| 5 | Helios | 视频生成 | 03-05 | 127 | 14B自回归扩散模型,单H100实时19.5 FPS长视频 |
| 6 | dLLM | 扩散LM | 03-02 | 115 | 统一扩散语言模型框架,支持LLaDA/Dream复现与微调 |
| 7 | T2S-Bench & SoT | 结构化推理 | 03-05 | 105 | 结构化思维提示+1.8K样本评测,8任务平均+5.7% |
| 8 | UniG2U-Bench | 多模态 | 03-04 | 79 | 30+模型评测发现统一模型普遍弱于基础VLM |
| 9 | CUDA Agent | 代码Agent | 03-02 | 75 | Agentic RL训练CUDA专家,100%超越torch.compile |
| 10 | SWE-rebench V2 | 代码Agent | 03-03 | 75 | 语言无关SWE任务流水线,规模化构建RL训练环境 |
| 11 | MOOSE-Star | 科学发现 | 03-06 | 74 | 打破组合复杂度壁垒,RL驱动科学假说生成训练 |
| 12 | Meta FAIR 多模态 | 多模态预训练 | 03-04 | 69 | 从头预训练揭示RAE/数据协同/MoE四大设计准则 |
| 13 | RubricBench | 评测 | 03-03 | 51 | 模型生成评分标准与人类标准的对齐程度评测基准 |
| 14 | BeyondSWE | 代码Agent | 03-04 | 50 | 500个跨仓库任务暴露代码Agent能力缺口,<45% |
| 15 | 空间理解+奖励 | 图像生成 | 03-02 | 47 | SpatialReward 数据集+奖励模型强化文生图空间关系 |
| 16 | SkillNet | Agent | 03-06 | 44 | 创建/评测/连接AI技能的统一框架 |
| 17 | OpenAutoNLU | NLU | 03-03 | 43 | 开源NLU自动机器学习库 |
| 18 | MMR-Life | 多模态 | 03-03 | 42 | 真实场景多模态记忆检索基准 |
| 19 | CHIMERA | 推理数据 | 03-03 | 42 | 9K紧凑合成推理数据,4B模型追平235B |
| 20 | DARE | R生态Agent | 03-06 | 41 | 分布感知检索嵌入对接LLM与R统计生态 |
| 21 | RITranslation | 多语言 | 03-02 | 39 | 自动化基准翻译框架+T-RANK多轮竞争排序 |
| 22 | Mode-Mean Video | 视频生成 | 03-02 | 36 | 模式求解+均值求解解耦局部保真与长程一致性 |
| 23 | Qwen3-Coder-Next | 代码模型 | 03-04 | 36 | 80B总参/3B激活MoE代码Agent,逼近十倍体量模型 |
| 24 | VGGT-Det | 3D检测 | 03-03 | 33 | 挖掘VGGT内部先验的无传感器几何3D检测 |
| 25 | CMI-RewardBench | 音乐 | 03-03 | 32 | 音乐奖励模型的组合与感知指令评测 |
| 26 | Mix-GRM | 奖励模型 | 03-04 | 32 | 广度+深度双CoT让生成式奖励模型提升8.2% |
| 27 | AgentVista | 多模态Agent | 03-06 | 30 | 超高难度多模态Agent评测基准 |
| 28 | RoboPocket | 机器人 | 03-06 | 28 | 手机即时改善机器人策略 |
| 29 | Kling-MotionControl | 视频生成 | 03-04 | 24 | 分治策略统一DiT框架实现全身角色动画精细可控 |
| 30 | Proact-VL | 视频LLM | 03-05 | 24 | 主动式实时视频LLM,支持AI伴侣场景 |
本周(3月1日—7日)HuggingFace 共收录 151 篇论文,热度最高的研究方向呈现三条清晰主线。
第一条主线:通用表征与统一架构持续深化。Utonia(138票)用单个 Point Transformer 跨越遥感/LiDAR/室内/物体/视频五大点云域,是稀疏3D数据基础模型的关键一步;Meta FAIR 的多模态预训练探索(69票)系统隔离各设计因素,揭示 RAE 表征和 MoE 架构是多模态基础模型的关键拼图;UniG2U-Bench(79票)则给出了「统一模型的生成能力并未普遍提升理解」的严肃实证。
第二条主线:强化学习从对话对齐向专业工程能力扩展。HACRL(136票)提出异构Agent协同RL新范式——不同结构模型在训练时共享验证轨迹互学习,推理时各自独立运行;CUDA Agent(75票)把 Agentic RL 推到 GPU Kernel 这一极度专业领域,在最难等级的 KernelBench 上超越最强专有模型约 40%;MOOSE-Star(74票)则把 RL 引入科学假说生成,打破了直接训练 P(h|b) 的组合复杂度壁垒。
第三条主线:扩散模型在语言和视频两端同步框架化。dLLM(115票)为扩散语言模型建立了统一开发框架;Helios(127票)实现 14B 模型单卡实时长视频生成;OmniLottie(131票)把扩散/自回归生成引入矢量动画格式,并构建了 MMLottie-2M 大规模数据集。
Utonia:统一五域点云的自监督编码器,机器人操作提升 8.3%

点云数据来自遥感、自动驾驶 LiDAR、室内 RGB-D、CAD 模型等截然不同的传感器,尺度、密度、采样模式差异极端,此前自监督点云模型只能在单一域内训练(如 Sonata 在室内/室外分开预训练,Concerto 引入视频点云但仍排除物体域)。Utonia 迈出关键一步:用单一 Point Transformer 编码器,同时覆盖遥感、室外 LiDAR、室内 RGB-D 序列、物体 CAD 模型、视频点云五大域进行联合自监督预训练。
核心挑战在于处理域间颜色/法向量输入的不一致性。Utonia 引入自适应 C./N. 机制:当某域缺乏颜色或法向量时自动降级,避免模型被域特异性捷径主导而丢失跨域可迁移几何语义。预训练使用 masked autoencoding 范式。
实验表明,联合训练带来跨域涌现行为:ScanNet 语义分割超越单域预训练 2.1 mIoU,nuScenes 检测提升 1.8 NDS。更值得关注的是 Utonia 表征向下游的迁移——接入视觉语言动作策略(VLA),机器人操作成功率提升 8.3%;接入 VLM 用于空间推理同样有增益。这表明通用点云表征不仅惠及感知任务,也能提升具身 AI 与多模态推理。
HACRL:异构Agent共享验证轨迹互相学习,训练协同推理独立
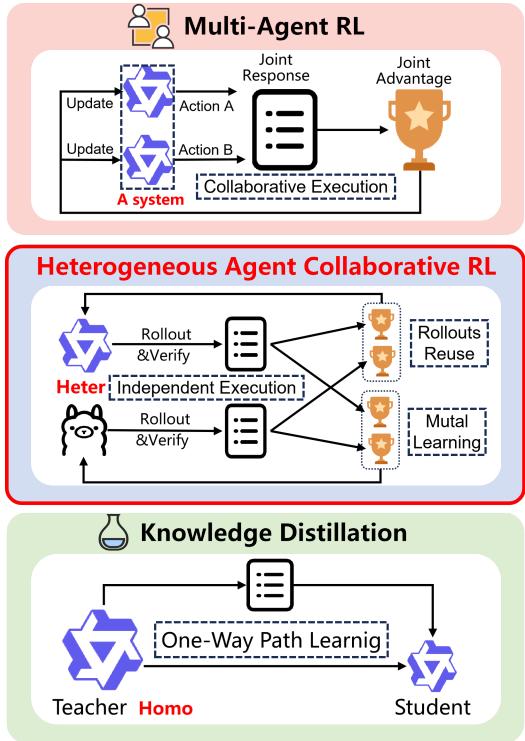
RLVR(可验证奖励强化学习)通过可检验奖励信号直接对齐推理能力,已成为强化 LLM 推理的核心范式。但其瓶颈在于昂贵的在线采样:每个 Agent 需要自己生成轨迹、做验证,而这些中间结果只用于自身训练,多个 Agent 面对相同任务时大量重复计算。
HACRL(异构 Agent 协同强化学习)提出新范式:训练时协同优化、推理时独立执行。异构 Agent(参数量、架构或预训练数据不同)共享彼此生成的经过验证的轨迹(rollouts),互相从对方的成功/失败中学习,实现双向知识迁移,而非蒸馏中的单向师生关系。在此基础上提出 HACPO 算法,引入四项机制处理能力差异和策略分布偏移:无偏优势估计、分布加权、截断和归一化,并提供理论保证。
在多种异构模型组合(不同参数量和系列)和推理基准上,HACPO 始终让所有参与 Agent 获得提升,平均超越 GSPO 3.3%,且仅用一半 rollout 成本。这验证了异构协同能有效突破每个模型自身的能力边界。
OmniLottie:参数化 Lottie Token 驱动的多模态矢量动画生成
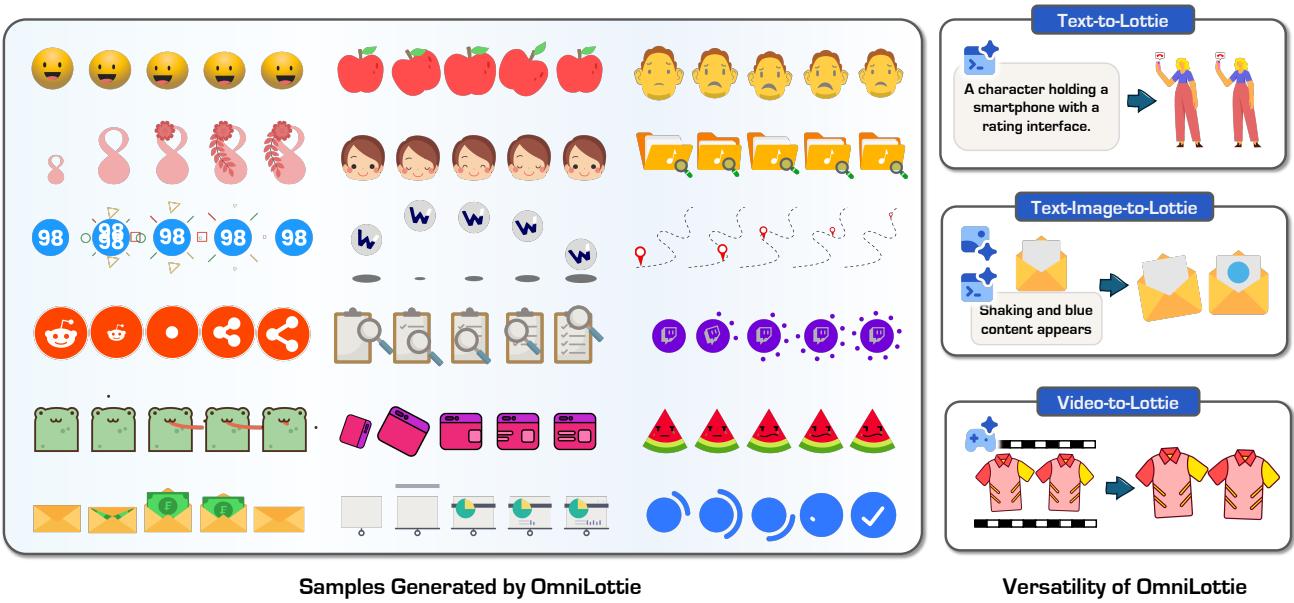
Lottie 是一种广泛采用的矢量动画格式,将所有形状、效果和运动参数存储在单个 JSON 文件中,具有跨平台兼容性强、轻量级可编辑的优势。但直接让语言模型生成 Lottie JSON 存在关键问题:原始 JSON 充斥大量不变的结构性元数据和格式 Token,语义信息密度极低,导致现有 LLM 生成成功率低且难以控制动画内容。
OmniLottie 的核心贡献是设计了专用 Lottie Tokenizer,将 JSON 文件转换为形状、动画函数和控制参数的结构化指令序列——大幅压缩序列长度同时保留语义。基于此 Tokenizer,OmniLottie 在预训练 VLM 上进行端到端微调,支持文本→Lottie、图文→Lottie、视频→Lottie 三类生成任务。为支持大规模训练,研究团队还构建了 MMLottie-2M,包含 200 万条专业设计矢量动画及配套文本/视觉标注。
广泛实验验证 OmniLottie 能生成语义一致、动效自然、格式合规的矢量动画,生成成功率显著优于直接输出 JSON 的基线方法。这项工作填补了生成式 AI 在轻量级矢量媒介上的空白,对设计工具和创意内容生产有直接应用价值。
ADE-CoT:难度感知自适应图像编辑 CoT,2× 加速同时提升质量
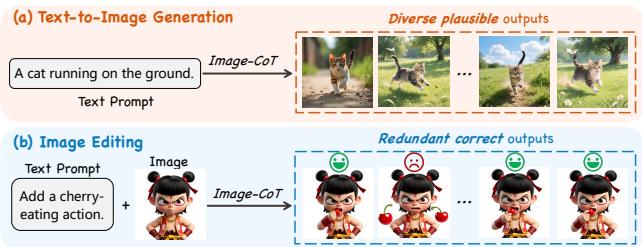
Image Chain-of-Thought(Image-CoT)通过在推理时生成多个候选方案再选优来提升图像生成质量,已在文生图(T2I)任务上取得显著效果。但将其直接迁移到图像编辑面临三个根本性挑战:(1) 固定采样预算在简单编辑上浪费计算;(2) 用通用 MLLM 打分在早期阶段不可靠;(3) 目标导向的编辑任务中大规模采样产生大量冗余正确结果。
ADE-CoT(自适应编辑 CoT)针对性地提出三项策略:① 难度感知资源分配,根据预估编辑难度动态分配采样预算;② 编辑专用早期验证,利用区域定位和字幕一致性评估(而非通用 MLLM 打分)做候选筛选;③ 深度优先机会性停止,由实例级验证器引导,一旦找到意图对齐结果即终止。三者结合适用于 Step1X-Edit、BAGEL、FLUX.1 Kontext 等多个前沿编辑模型。
在三个基准上的大量实验表明,ADE-CoT 在可比采样预算下 超越 Best-of-N 同时实现 2× 以上加速,为图像编辑的测试时扩展提供了高效实用的解决方案。
Helios:14B 自回归扩散模型,单卡 H100 实时 19.5 FPS 长视频生成
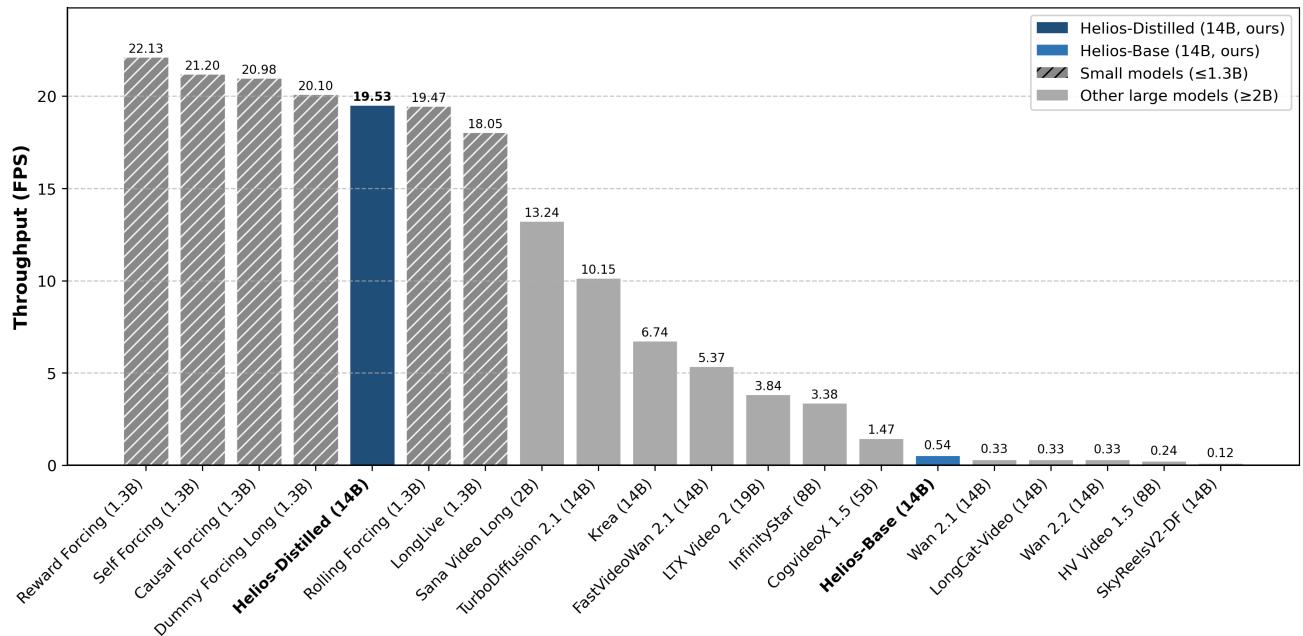
当前视频生成的前沿困境:更大参数量带来更好质量,但推理速度和长视频稳定性严重不足。现有实时生成方法通常依赖 1.3B 小模型,复杂运动和高频细节表现有限;Krea-RealTime-14B 将规模扩大,但在单 H100 上仅达到 6.7 FPS。Helios 在三个关键维度同时突破:
(1) 抗漂移训练无需特殊启发式:分析长视频漂移失败模式,提出训练策略在训练时显式模拟漂移,从根源消除重复运动,无需 Self-Forcing、error-bank 或关键帧采样;(2) 实时生成无需标准加速技巧:通过大幅压缩历史和噪声上下文、减少采样步数,计算成本与 1.3B 模型相当;(3) 训练无需并行或分片框架:通过基础设施级优化,80GB GPU 内存可容纳最多四个 14B 模型,实现图像扩散量级的 batch size。
在短视频和长视频生成基准上,Helios 始终优于蒸馏模型,同时接近基础大模型的质量。团队计划开放代码、基础模型和蒸馏模型权重。
dLLM:扩散语言模型的统一开源框架,降低 DLM 研究门槛
扩散语言模型(DLMs)已展现出自回归语言模型之外的独特优势:支持迭代精化、灵活引导和高效解码。然而现有研究中的关键组件分散在各个 ad-hoc 代码库中,缺乏透明实现,使得复现、对比和扩展工作都极为困难。dLLM 是来自 UC Berkeley 和 UIUC 的开源框架,围绕三个核心组件统一 DLM 开发管线:
(1) 训练模块:覆盖最常见目标——Masked Diffusion 和 Block Diffusion——扩散建模逻辑与模型架构解耦,新目标和变体只需最小改动即可集成。用户可直接复现和微调 LLaDA、Dream 等现有大型 DLM;(2) 推理模块:轻量抽象支持即插即用的推理算法(含优化高效解码算法)而无需修改模型实现;(3) 评测模块:提供跨模型统一评测接口,可复现各模型官方结果。此外还发布了从 BERT 编码器或自回归 LM 转换为 DLM 的最小可复现配方,以及对应的小型 DLM 检查点。
dLLM 的意义在于:扩散语言模型正从各自为战走向标准化生态,就像 Hugging Face Transformers 对自回归模型所做的那样。这是 DLM 领域基础设施建设的重要里程碑。
T2S-Bench & Structure-of-Thought:文本结构化推理的评测与提示新范式
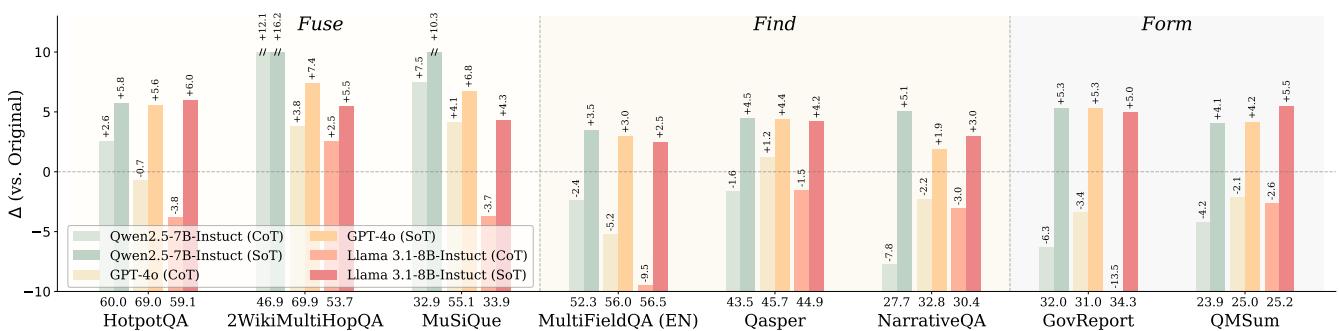
人类处理复杂阅读任务时会自然地提取关键节点、推断关系、构建结构——这种结构化过程是高质量理解的基础。类比到 LLM,是否显式引导模型构建文本中间结构也能系统性提升性能?这篇论文给出了肯定答案。
Structure-of-Thought(SoT)是一种通用提示策略:指导模型在生成最终答案前,先将文本结构化为关键节点和关系。来自 Duke 和 Meta 的团队验证 SoT 在 8 个主流文本处理任务和 3 个模型系列上一致显著提升,表明文本结构是增强各类下游任务的通用中间表征。基于此洞见,团队构建了 T2S-Bench,首个专门评测和提升模型文本到结构能力的基准:1800 个样本,跨 6 个科学领域,32 种结构类型,覆盖 45 个主流模型。
关键评测发现:45 个主流模型在多跳推理任务上平均准确率仅 52.1%,即使最先进模型在端到端提取任务中节点准确率也只有 58.1%。文本结构化能力是当前 LLM 的薄弱环节,SoT 和 T2S-Bench 提供了互补的提升路径:前者通过提示,后者通过微调数据。
UniG2U-Bench:统一多模态模型的生成能力真的提升了理解吗?
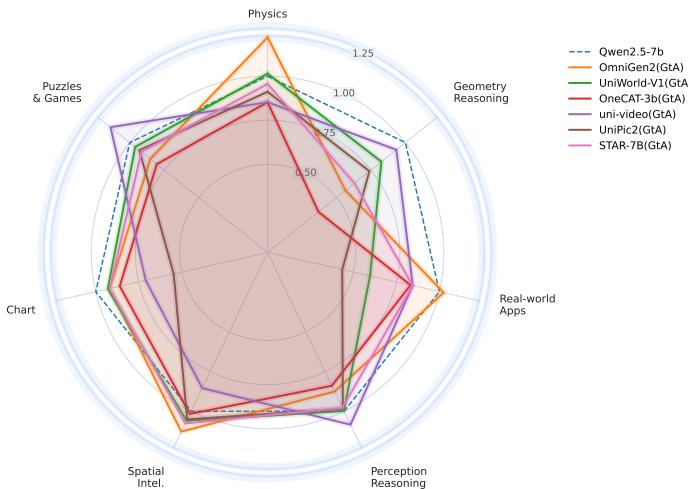
统一多模态模型(Bagel、OmniGen、Show-o、Janus 等)宣称「理解+生成一体化」带来双向互利,但生成能力是否真的提升了理解这一核心问题一直缺乏系统验证。UniG2U-Bench 填补这一空白:将生成到理解(G2U)评测分为 7 大维度、30 个子任务,涵盖需要不同程度显式/隐式视觉变换的场景(空间智能、视觉错觉、几何推理、多轮推理等)。
研究严格将统一模型与其基础 VLM 配对,在相同推理协议下隔离 G2U 效果,评测了 30+ 模型。三个核心发现:(1) 统一模型普遍不如基础 VLM,Generate-then-Answer 推理通常比直接推理更差;(2) 仅在空间智能、视觉错觉、多轮推理子任务中出现一致性提升;(3) 具有相似推理结构的任务和共享架构的模型表现出相关的行为模式,表明统一训练诱导了类别一致的归纳偏置。
结论并非全盘否定统一模型,而是指向更精细的训练策略需求:需要更多样化的训练数据和新范式,才能真正将生成能力转化为理解优势。
CUDA Agent:大规模 Agentic RL 训练 GPU Kernel 专家,KernelBench 超越最强专有模型 40%
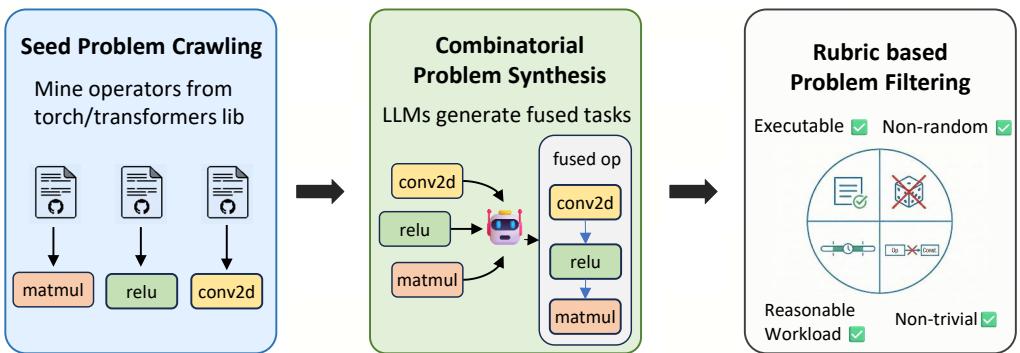
GPU Kernel 优化是现代深度学习基础设施的核心,但这是一项需要深厚硬件知识的高度专业化任务。尽管 LLM 在通用编程上表现出色,现有方法在 CUDA Kernel 生成上仍然无法与 torch.compile 这样的编译器系统竞争,更不用说与人类专家相比。
CUDA Agent 是一个大规模 Agentic RL 系统,通过三个互补维度提升模型的 CUDA Kernel 编码能力:(1) 可扩展数据合成管线:生成覆盖广泛难度等级的训练问题,支持有效的课程式 RL 训练;(2) 技能增强的 CUDA 开发环境:配备自动化验证和性能分析脚本提供可靠奖励信号,系统级权限隔离防止奖励作弊;(3) RL 算法稳定性技术:提出 Actor 和 Critic 的多阶段预热策略解决训练不稳定性。
CUDA Agent 在 KernelBench 上取得 SOTA:Level-1 和 Level-2 100% 超越 torch.compile,Level-3(最难级别)92% 超越率,在最难设置上超越 Claude Opus 4.5 和 Gemini 3 Pro 约 40%。这是 LLM 首次在这一专业任务上实现系统性突破。
SWE-rebench V2:语言无关的 SWE 任务规模化采集,支撑 RL 训练
软件工程 Agent(SWE)的快速进步很大程度上由强化学习驱动,但 RL 训练面临关键约束:缺乏大规模、可复现执行环境且测试套件可靠的任务集合。现有基准规模有限、多样性不足,且大多仅针对 Python 等高资源语言生态,制约了 SWE Agent RL 训练的规模化。
SWE-rebench V2 提出了一个语言无关的自动化管线,用于从真实世界代码仓库中大规模采集可执行 SWE 任务并构建 RL 训练环境:(1) 交互式安装 Agent 合成仓库特定的安装和测试流程;(2) LLM 集成过滤(ensemble of LLM judges)消除不健全实例;(3) 自动化适配多语言仓库,不依赖特定语言生态的假设。
SWE-rebench V2 的核心价值在于解决了 SWE Agent RL 训练的数据基础设施瓶颈,为多样化、大规模、跨语言的代码工程 Agent 训练提供了可扩展的数据供给方案。
MOOSE-Star:打破组合复杂度壁垒,用 RL 直接训练科学假说生成
LLM 在科学发现领域的应用正在快速扩展,但现有研究集中在推理阶段或反馈驱动训练,对于直接建模生成推理过程 P(假说|背景) 的训练探索不足。根本原因:从庞大知识库中检索和组合启发信息,天然面临 O(N^k) 的组合复杂度,使得直接训练在数学上不可行。
MOOSE-Star 提出统一框架打破这一壁垒:通过分解生成过程,在最优情况下将复杂度从 O(N^k) 降至 O(N+k),同时保持可扩展推理。框架支持两种互补的训练策略——基于实例的 RL 与数据驱动的知识蒸馏——以及在对齐 RLVR 设置下的融合。
研究团队同步发布了 TOMATO-Star 科学发现数据集和 MOOSE-Star 模型检查点。这项工作为 AI 辅助科研开辟了新方向:将生成式科学推理从纯推理阶段应用扩展到可系统训练优化的范式。
Meta FAIR 多模态预训练:从头实验揭示 RAE、数据协同与 MoE 的四大设计准则
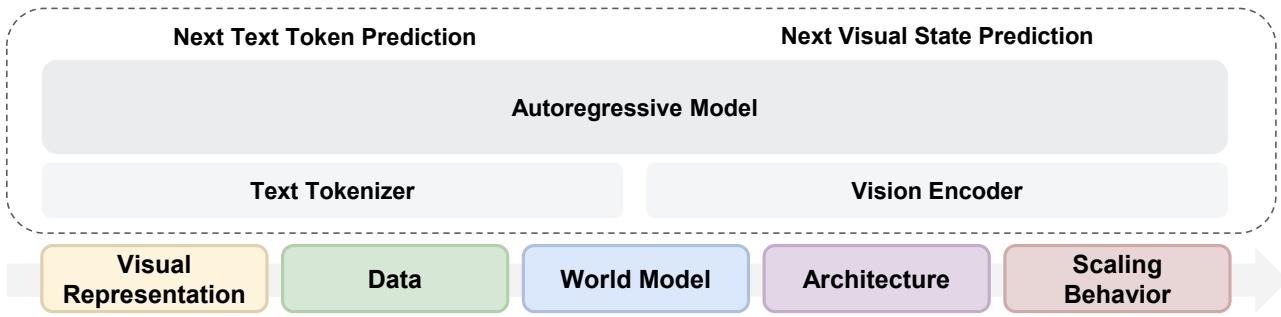
视觉世界是推动基础模型超越语言的关键轴心,但原生多模态模型的设计空间仍然不透明——哪些选择真正重要?来自 Meta FAIR 和 NYU(Yann LeCun 等参与指导)的团队通过严格控制变量的从头预训练实验,在不依赖任何语言预训练的前提下,系统隔离多模态预训练的核心因素。实验框架采用 Transfusion:语言用下一个 Token 预测,视觉用扩散。
四个关键发现:(1) RAE(Reconstruction Autoencoder)是最优统一视觉表征,同时擅长理解和生成;(2) 视觉和语言数据互补,联合训练产生跨模态协同效应;(3) 世界建模能力从通用训练中自然涌现,无需专项设计;(4) MoE 架构高效且自然诱导模态专业化,通过 IsoFLOP 分析揭示视觉比语言需要更多数据的缩放不对称性,MoE 恰好调和了这种不对称。
这项工作为多模态基础模型的设计提供了迄今最系统的从头实验指导,对领域内如何构建高效多模态基础模型具有重要参考价值。
RubricBench:评分标准对齐——模型生成的 Rubric 与人类标准有多远?
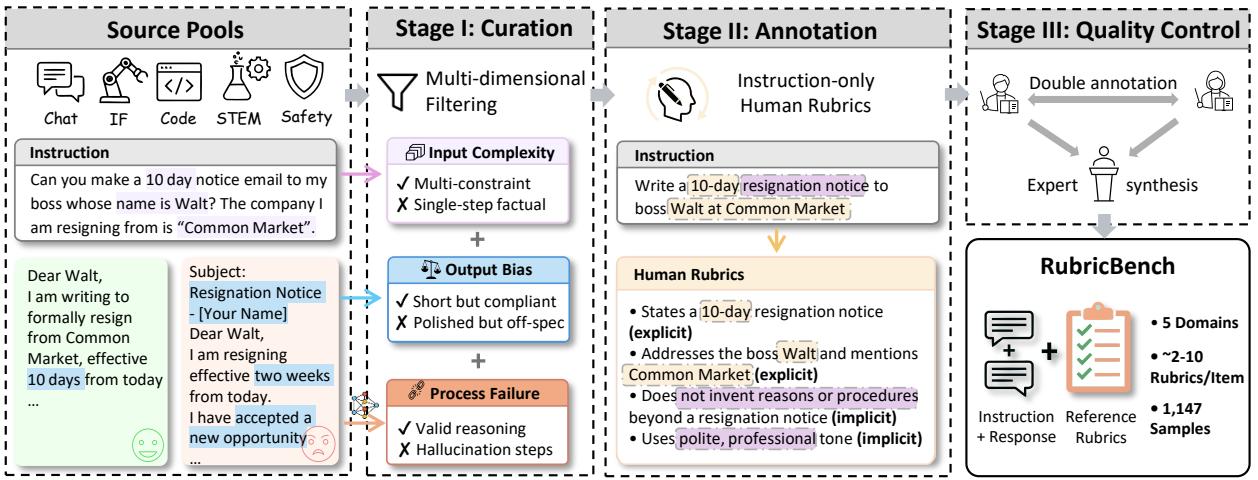
随着 LLM 对齐从简单补全发展到复杂生成,奖励模型越来越多地转向基于 Rubric(评分标准)的评估来减轻表面偏见。这类 Rubric 引导评估方法的有效性,很大程度上依赖模型生成的 Rubric 与人类标准的对齐程度——但这一能力此前缺乏统一基准评测。
RubricBench 填补这一空白,构建了专门评测这一对齐程度的基准:测试模型能否生成与人类评估者一致的评分标准,覆盖写作质量、代码正确性、推理链等多个维度的复杂生成任务。基准的核心贡献在于将「模型能打出正确分数」与「模型能生成对人类有意义的评分框架」这两个不同能力区分开来。
RubricBench 的意义在于:随着 AI 评测越来越依赖 LLM-as-Judge 和基于 Rubric 的自动评估,理解模型生成评估框架的质量与局限性变得尤为重要,这对 RLHF 数据质量和 AI 对齐研究都有直接影响。
BeyondSWE:代码 Agent 走出单仓库修 Bug 舒适区,500 个跨域任务揭示能力缺口
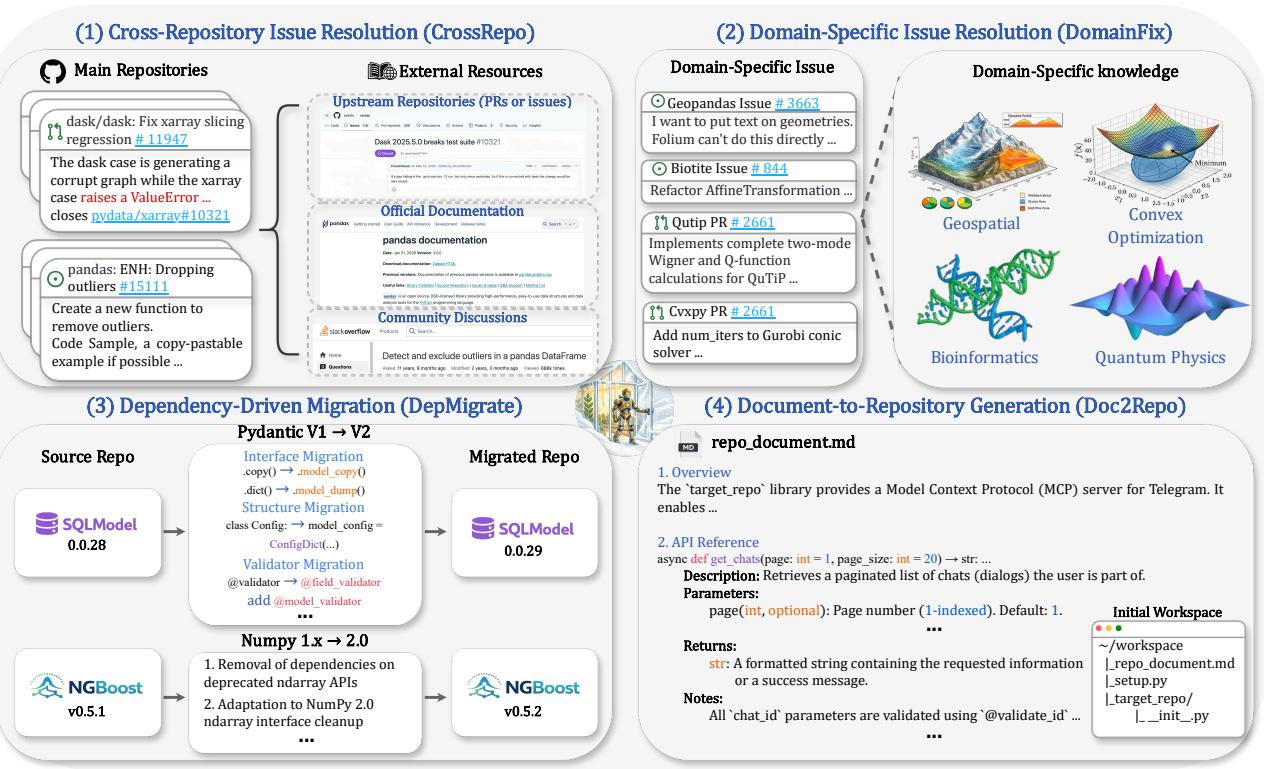
SWE-bench 已成为代码 Agent 的标准评测,但其任务本质上局限于单仓库内的函数级 Bug 修复,与真实工程场景的需求存在显著差距。BeyondSWE 沿解决范围和知识范围两个轴系统扩展评测,500 个真实实例覆盖四类全新设置:CrossRepo(跨仓库推理)、DomainFix(领域专用修复,需要专业领域知识)、DepMigrate(依赖迁移,跨版本或跨库适配)、Doc2Repo(整库从文档生成)。
实验结果清晰暴露当前代码 Agent 的系统性能力缺口:即使是最强前沿模型,成功率也低于 45%,且没有任何模型在所有任务类型上一致表现良好。研究团队同时开发了集成深度搜索的 SearchSWE 框架,但搜索增强效果并不一致,在某些任务上甚至降低性能。
空间理解增强文生图:SpatialReward 数据集与奖励模型强化空间关系生成
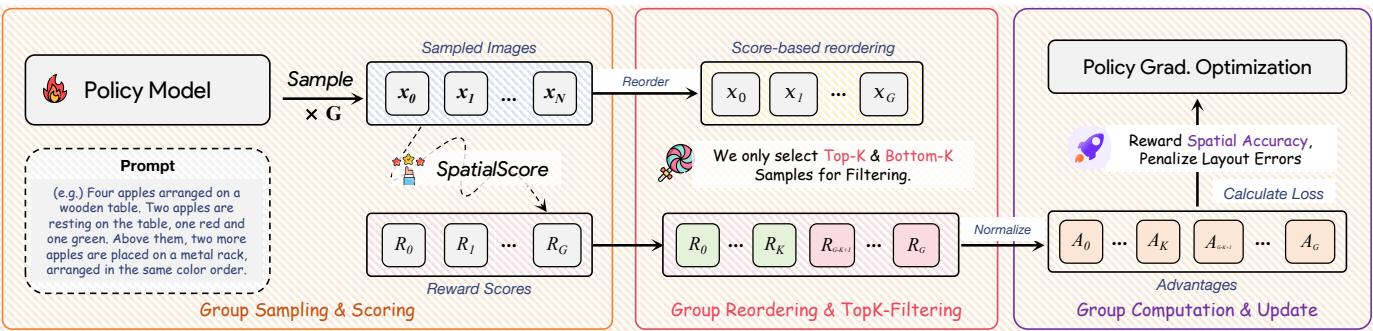
文生图模型在视觉保真度和创意表达上取得了显著进步,但对于编码复杂空间关系的提示(如「红色球在蓝色立方体左侧,圆柱在两者后方」),现有模型仍然频繁失败,往往需要多次采样才能得到正确结果。
本文提出一种针对性增强方案:首先构建 SpatialReward-Dataset,包含超过 80,000 个偏好对,明确标注空间关系准确性;在此基础上训练 SpatialScore 奖励模型,专门评估文生图结果中空间关系的准确性,在空间评估任务上超越领先专有模型;最后将 SpatialScore 用于引导现有文生图模型的推理过程,在不改变模型权重的前提下显著提升空间关系生成准确率。
这项工作展示了针对特定能力缺陷构建专用奖励模型的有效路径:用高质量偏好数据+精细评估维度来弥补通用奖励模型在空间理解上的不足,对文生图的可靠性提升有实践意义。
3月第一周值得关注的三个信号
-
RL 的战场从对话对齐延伸到专业工程
本周多篇高票论文将强化学习用于专业技术领域:CUDA Kernel(CUDA Agent)、科学假说生成(MOOSE-Star)、异构 Agent 协同训练(HACRL)。RL+可验证奖励的「RLVR」范式正在快速泛化,从数学推理向更专业、更难量化的工程领域扩展——但需要相应领域的精细环境和奖励设计。
-
「大一统」叙事遭遇严肃质疑
UniG2U-Bench 对 30+ 统一多模态模型的系统评测发现,生成能力并未普遍提升理解,统一模型整体弱于基础 VLM。BeyondSWE 则揭示代码 Agent 在跨仓库场景下成功率不足 45%。这些实证研究提示:在宣称「统一」或「通用」之前,需要更严格的多维度评测。
-
基础设施建设成为研究亮点
dLLM(扩散语言模型统一框架)、SWE-rebench V2(语言无关 SWE 任务采集管线)、OmniLottie(MMLottie-2M 矢量动画数据集)分别在不同子领域填补了基础设施空白。这类「工具性」研究正在获得更高的社区认可度,预示着各子领域从探索期走向成熟期。
参考链接
- [1] Utonia — huggingface.co/papers/2603.03283 · paperscope.ai/hf/2603.03283
- [2] HACRL — huggingface.co/papers/2603.02604 · paperscope.ai/hf/2603.02604
- [3] OmniLottie — huggingface.co/papers/2603.02138 · paperscope.ai/hf/2603.02138
- [4] ADE-CoT — huggingface.co/papers/2603.00141 · paperscope.ai/hf/2603.00141
- [5] Helios — huggingface.co/papers/2603.04379 · paperscope.ai/hf/2603.04379
- [6] dLLM — huggingface.co/papers/2602.22661 · paperscope.ai/hf/2602.22661
- [7] T2S-Bench & SoT — huggingface.co/papers/2603.03790 · paperscope.ai/hf/2603.03790
- [8] UniG2U-Bench — huggingface.co/papers/2603.03241 · paperscope.ai/hf/2603.03241
- [9] CUDA Agent — huggingface.co/papers/2602.24286 · paperscope.ai/hf/2602.24286
- [10] SWE-rebench V2 — huggingface.co/papers/2602.23866 · paperscope.ai/hf/2602.23866
- [11] MOOSE-Star — huggingface.co/papers/2603.03756 · paperscope.ai/hf/2603.03756
- [12] Beyond Language Modeling (Meta FAIR) — huggingface.co/papers/2603.03276 · paperscope.ai/hf/2603.03276
- [13] RubricBench — huggingface.co/papers/2603.01562 · paperscope.ai/hf/2603.01562
- [14] BeyondSWE — huggingface.co/papers/2603.03194 · paperscope.ai/hf/2603.03194
- [15] SpatialReward — huggingface.co/papers/2602.24233 · paperscope.ai/hf/2602.24233
感谢你读完这份周报。本周 151 篇论文里,RL 的边界在继续扩张,从推理数学到 GPU Kernel 再到科学假说;「统一模型」的宣称在接受更严格检验;基础设施建设正在悄悄填补各个子领域的工具空白。
下周继续关注三件事:(1) 异构 Agent 协同 RL 有没有更多跟进工作;(2) 扩散语言模型生态在 dLLM 框架基础上如何加速;(3) 视频生成实时化路线的竞争格局如何演变。
如果这份周报对你有帮助,欢迎顺手点赞、在看、转发三连,让更多关注 AI 研究的朋友看到。想第一时间收到下周周报,记得给公众号加个星标。
© 2026 AI Insight · 机智流 · 本文由 AI 生成,可能有误