速览目录 · Top 30 本周热榜
| # | 论文 | 领域 | 日期 | Votes | 一句话 |
|---|---|---|---|---|---|
| 1 | Utonia | 3D视觉 | 03-04 | 153 | 单编码器横跨五大点云域,跨域涌现提升机器人操作8.3% |
| 2 | HACRL | 多智能体RL | 03-05 | 151 | 异构Agent共享验证轨迹互学,训练协同推理独立 |
| 3 | Helios | 视频生成 | 03-05 | 146 | 14B自回归扩散模型单H100实时19.5 FPS长视频 |
| 4 | OmniLottie | 矢量动画 | 03-03 | 134 | 参数化Lottie Token自回归生成,多模态驱动矢量动画 |
| 5 | ADE-CoT | 图像编辑 | 03-03 | 132 | 难度感知预算分配+早期剪枝,图像编辑CoT 2倍加速 |
| 6 | dLLM | 扩散LM | 03-02 | 123 | 统一扩散语言模型框架,支持LLaDA/Dream复现与微调 |
| 7 | T2S-Bench & SoT | 结构化推理 | 03-05 | 110 | 结构化思维提示+1.8K样本评测,8任务平均+5.7% |
| 8 | MOOSE-Star | 科学发现 | 03-06 | 83 | 打破O(N^k)组合壁垒,RL驱动科学假说生成训练 |
| 9 | CUDA Agent | 代码Agent | 03-02 | 80 | Agentic RL训练CUDA专家,100%超越torch.compile |
| 10 | UniG2U-Bench | 多模态 | 03-04 | 80 | 30+模型评测发现统一模型普遍弱于基础VLM |
| 11 | SWE-rebench V2 | 代码Agent | 03-03 | 77 | 语言无关SWE任务采集管线,规模化构建RL训练环境 |
| 12 | Meta FAIR 多模态 | 多模态预训练 | 03-04 | 77 | 从头预训练揭示RAE/数据协同/MoE四大设计准则 |
| 13 | SkillNet | Agent | 03-06 | 68 | 20万+技能库,统一创建/评测/连接AI技能基础设施 |
| 14 | RubricBench | 评测 | 03-03 | 53 | 模型生成评分标准与人类标准的对齐程度评测基准 |
| 15 | BeyondSWE | 代码Agent | 03-04 | 52 | 500个跨仓库任务暴露代码Agent能力缺口,<45% |
| 16 | SpatialReward | 图像生成 | 03-02 | 50 | SpatialReward 数据集+奖励模型强化文生图空间关系 |
| 17 | DARE | R生态Agent | 03-06 | 45 | 分布感知检索嵌入对接LLM与R统计生态 |
| 18 | CHIMERA | 推理数据 | 03-03 | 44 | 9K紧凑合成推理数据,4B模型追平235B |
| 19 | OpenAutoNLU | NLU | 03-03 | 44 | 开源NLU自动机器学习库 |
| 20 | Qwen3-Coder-Next | 代码模型 | 03-04 | 43 | 80B总参/3B激活MoE代码Agent,逼近十倍体量模型 |
| 21 | MMR-Life | 多模态 | 03-03 | 42 | 真实场景多模态记忆检索基准 |
| 22 | RITranslation | 多语言 | 03-02 | 39 | 自动化基准翻译框架+T-RANK多轮竞争排序 |
| 23 | Mode-Mean Video | 视频生成 | 03-02 | 38 | 模式求解+均值求解解耦局部保真与长程一致性 |
| 24 | AgentVista | 多模态Agent | 03-06 | 36 | 超高难度多模态Agent评测基准 |
| 25 | VGGT-Det | 3D检测 | 03-03 | 34 | 挖掘VGGT内部先验的无传感器几何3D检测 |
| 26 | CMI-RewardBench | 音乐 | 03-03 | 32 | 音乐奖励模型的组合与感知指令评测 |
| 27 | Mix-GRM | 奖励模型 | 03-04 | 32 | 广度+深度双CoT让生成式奖励模型提升8.2% |
| 28 | RoboPocket | 机器人 | 03-06 | 30 | 手机即时改善机器人策略 |
| 29 | MemSifter | LLM记忆 | 03-05 | 27 | 结果驱动代理推理卸载LLM记忆检索 |
| 30 | Kling-MotionControl | 视频生成 | 03-04 | 26 | 分治策略统一DiT框架实现全身角色动画精细可控 |
本周(3月2日—8日)HuggingFace 共收录 151 篇论文,三条研究主线格外清晰。
第一条主线:「一个模型通吃」的基础模型路线持续推进与被质疑。Utonia(153票)用单个 Point Transformer 横跨遥感/LiDAR/室内/物体/视频五大点云域,验证了跨域联合训练的涌现效应;然而 UniG2U-Bench(80票)对 30+ 统一多模态模型的严格评测表明,生成能力并未普遍提升理解——「大一统」的承诺需要更精细的工程来兑现。
第二条主线:强化学习从通用推理向专业工程领域全面渗透。HACRL(151票)让异构Agent在训练阶段共享验证轨迹互相学习,推理时各自独立;CUDA Agent(80票)把 Agentic RL 推入 GPU Kernel 优化领域,在最难设置上超越 Claude Opus 4.5 约 40%;MOOSE-Star(83票)将 RL 引入科学假说生成,巧妙地把 O(N^k) 组合复杂度降至 O(N+k)。
第三条主线:实时生成与基础设施框架化齐头并进。Helios(146票)实现 14B 模型单 H100 实时 19.5 FPS 长视频生成;dLLM(123票)为扩散语言模型建立统一开发框架;SkillNet(68票)构建了超 20 万 AI 技能的可组合基础设施——各子领域正从探索期走向工程化。
Utonia:一个编码器统一五域点云,跨域涌现推动机器人操作提升 8.3%

点云数据来自遥感卫星、自动驾驶 LiDAR、室内 RGB-D、CAD 模型等截然不同的传感器,尺度、密度、采样模式差异极端。此前的自监督点云模型(如 Sonata、Concerto)只能在单一或少数域内训练。Utonia 用单一 Point Transformer 编码器,首次同时覆盖遥感、室外 LiDAR、室内 RGB-D 序列、物体 CAD 模型、视频点云五大域进行联合自监督预训练。
核心技术创新在于自适应颜色/法向量(C./N.)机制:不同域的输入模态不一致(有些有颜色无法向量,有些相反),Utonia 自动降级缺失模态,避免模型学到域特异性捷径,从而保留跨域可迁移的几何语义特征。预训练采用 masked autoencoding 范式。
实验验证了联合训练的跨域涌现效应:ScanNet 语义分割超越单域预训练 2.1 mIoU,nuScenes 检测提升 1.8 NDS。更关键的是 Utonia 表征在下游任务的迁移——接入 VLA 后机器人操作成功率提升 8.3%,接入 VLM 进行空间推理同样有增益。通用点云表征不仅惠及感知,也能提升具身 AI 与多模态推理。
HACRL:训练时协同、推理时独立——异构Agent共享轨迹互学的新范式
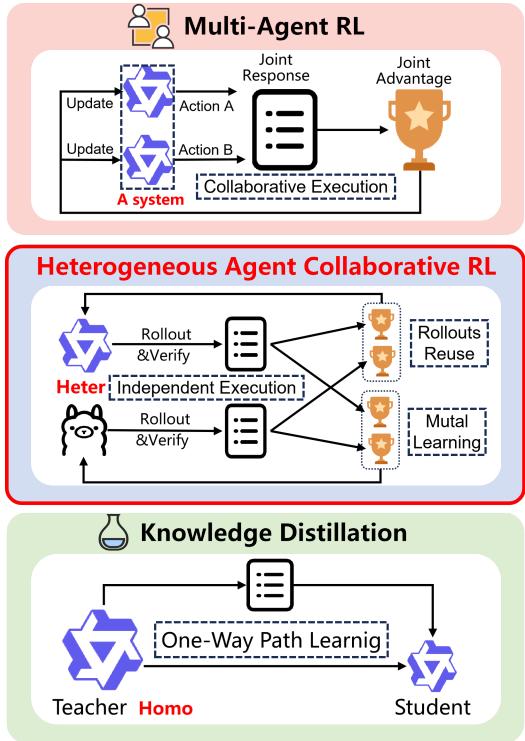
RLVR(可验证奖励强化学习)已成为强化 LLM 推理的核心方法,但面临昂贵的在线采样瓶颈:每个 Agent 自己生成轨迹、做验证,多个 Agent 面对同一任务时大量重复采样。HACRL 提出了一个全新范式:让不同结构的 Agent(参数量、架构或预训练数据各异)在训练阶段共享经过验证的推理轨迹,互相从对方的成功和失败中学习。
关键算法 HACPO 解决异构模型间能力差异和策略分布偏移的技术挑战,引入四项机制:无偏优势估计、分布加权、截断和归一化,并提供理论保证。与知识蒸馏的根本区别在于 HACRL 是双向互学而非单向师生关系——小模型能从大模型学到推理策略,大模型也能从小模型的成功路径中获得启发。
在多种异构模型组合和推理基准上,HACPO 让所有参与 Agent 都获得提升,平均超越 GSPO 3.3%,且采样成本减半。推理时各模型完全独立部署,无需协同开销。
Helios:14B 参数单 H100 实时 19.5 FPS——大模型长视频生成的速度新标杆
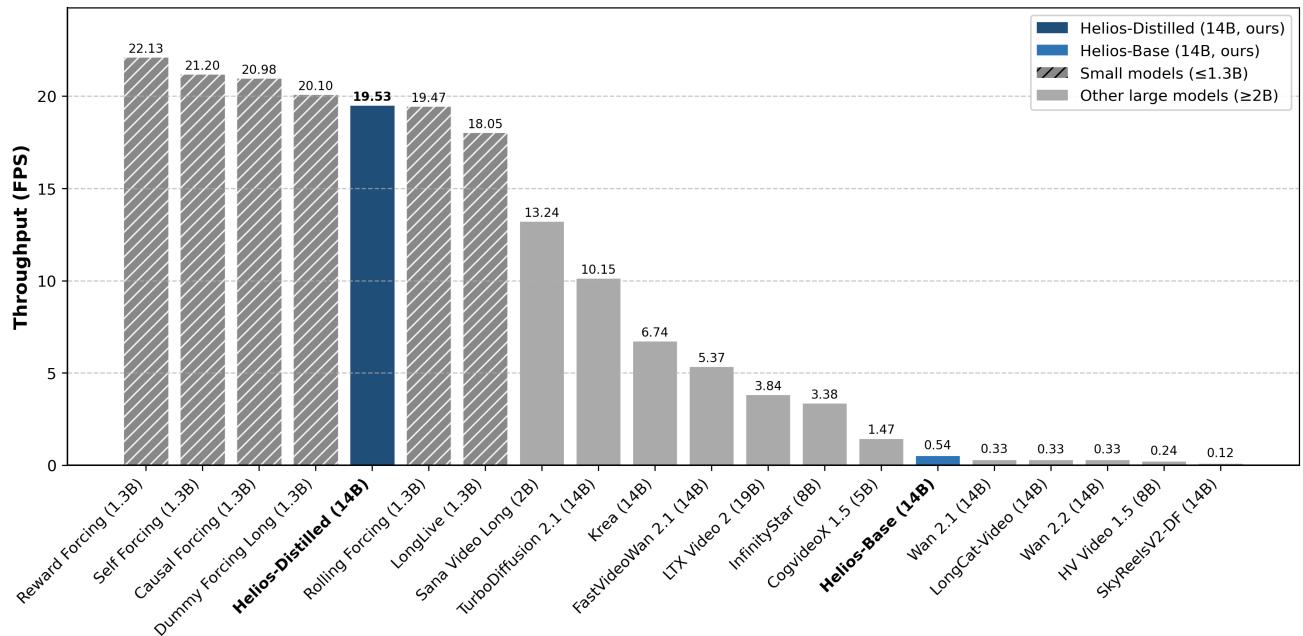
视频生成领域的核心矛盾:更大参数量带来更好质量,但推理速度和长视频稳定性严重不足。现有实时方案通常用 1.3B 小模型,复杂运动表现有限;Krea-RealTime-14B 虽扩大规模但单 H100 仅 6.7 FPS。Helios 在三个关键维度同时实现突破:
(1) 抗漂移训练:分析长视频漂移的失败模式,提出在训练时显式模拟漂移现象,从根源消除重复运动,无需 Self-Forcing 或关键帧采样等启发式方法;(2) 实时推理:通过大幅压缩历史上下文和噪声上下文、减少采样步数,使 14B 模型的计算成本接近 1.3B 模型;(3) 训练效率:基础设施级优化让 80GB GPU 内存可容纳多个 14B 模型实例。
在短视频和长视频基准上,Helios 始终优于蒸馏模型,同时接近基础大模型的生成质量。团队计划开源代码、基础模型和蒸馏模型权重。
OmniLottie:将矢量动画压缩为语义 Token,多模态指令驱动 Lottie 生成
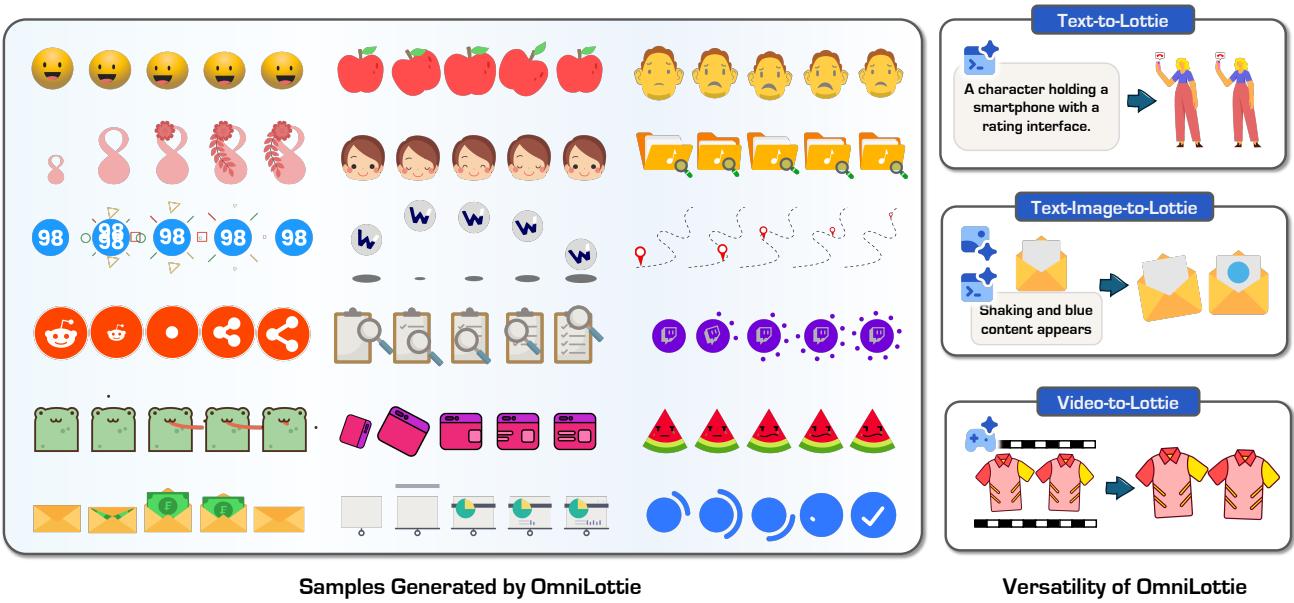
Lottie 是一种广泛使用的矢量动画格式,以 JSON 存储所有形状、效果和运动参数,具备跨平台兼容和轻量可编辑的优势。但直接让 LLM 生成 Lottie JSON 有本质困难:原始 JSON 充斥大量不变的结构性元数据,语义信息密度极低,导致生成成功率差且难以控制动画内容。
OmniLottie 的核心贡献是设计了专用 Lottie Tokenizer,把 JSON 文件转换为形状、动画函数和控制参数的结构化指令序列——大幅压缩序列长度同时保留完整语义。基于此 Tokenizer,在预训练 VLM 上端到端微调,支持文本→Lottie、图文→Lottie、视频→Lottie 三类任务。配套发布的 MMLottie-2M 数据集包含 200 万条专业设计矢量动画及文本/视觉标注。
实验验证 OmniLottie 生成的矢量动画语义一致、动效自然、格式合规,成功率显著优于直接输出 JSON 的基线。这项工作填补了生成式 AI 在轻量级矢量媒介上的空白。
ADE-CoT:图像编辑不是开放任务——难度感知自适应 CoT 实现 2× 加速
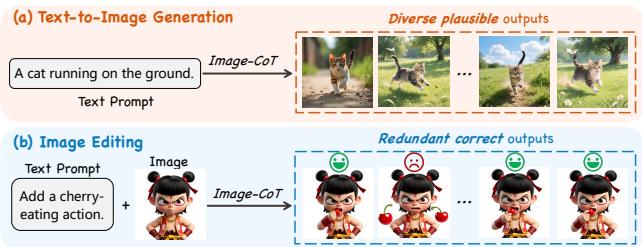
Image-CoT 通过生成多个候选方案再选优来提升图像质量,已在文生图任务上取得显著效果。但直接迁移到图像编辑面临三个问题:(1) 简单编辑上固定采样预算造成计算浪费;(2) 通用 MLLM 打分在早期阶段不可靠;(3) 目标导向任务中大量采样产生冗余正确结果。
ADE-CoT(自适应编辑 CoT)提出三项针对性策略:① 难度感知资源分配——根据预估编辑难度动态调整采样预算;② 编辑专用早期验证——用区域定位和字幕一致性评估替代通用打分做候选筛选;③ 深度优先机会性停止——由实例级验证器引导,一旦找到意图对齐的结果即终止。三者联合适用于 Step1X-Edit、BAGEL、FLUX.1 Kontext 等前沿编辑模型。
在三个基准上,ADE-CoT 在可比采样预算下 超越 Best-of-N 同时实现 2× 以上加速,为图像编辑的测试时计算扩展提供了高效方案。
dLLM:扩散语言模型的「Hugging Face Transformers」——训练/推理/评测统一框架
扩散语言模型(DLMs)展现了自回归之外的独特优势——迭代精化、灵活引导和高效解码。但现有关键组件分散在各个 ad-hoc 代码库中,复现和对比极为困难。dLLM 围绕三个核心组件统一 DLM 开发管线:
(1) 训练模块:覆盖 Masked Diffusion 和 Block Diffusion 等主流目标,扩散逻辑与模型架构解耦,新变体只需最小改动;用户可直接复现和微调 LLaDA、Dream 等开源 DLM。(2) 推理模块:轻量抽象支持即插即用的推理算法(含高效解码优化),无需改动模型实现。(3) 评测模块:跨模型统一评测接口,可复现各模型官方结果。同时发布从 BERT 编码器或自回归 LM 转换为 DLM 的最小可复现配方及对应检查点。
dLLM 的意义在于:扩散语言模型正从各自为战走向标准化生态,就像 Hugging Face Transformers 为自回归模型做到的那样。这是 DLM 领域基础设施建设的里程碑。
T2S-Bench & Structure-of-Thought:让 LLM 先画结构再答题,8 任务平均 +5.7%
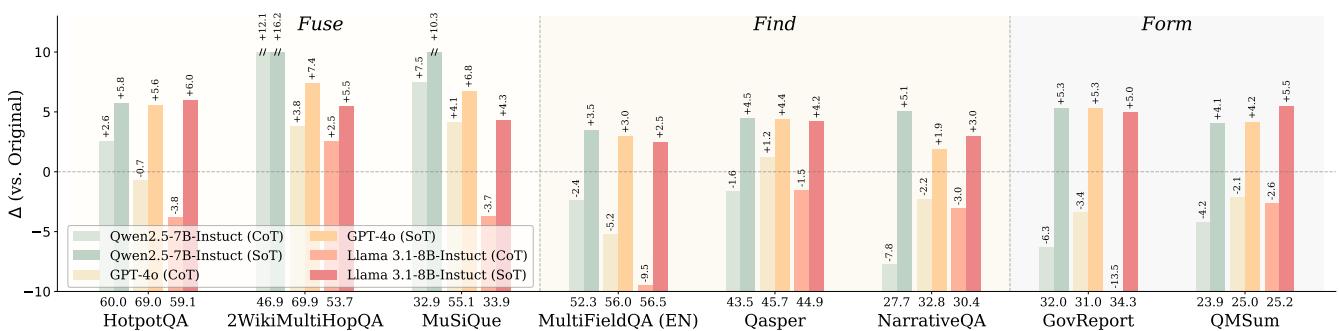
人类处理复杂阅读任务时自然地提取关键节点、推断关系、构建结构——这种结构化过程是高质量理解的基础。Structure-of-Thought(SoT)是一种通用提示策略:指导模型在生成最终答案前,先将文本结构化为关键节点和关系,在 8 个主流文本处理任务和 3 个模型系列上一致显著提升性能。
基于此洞见,团队构建了 T2S-Bench——首个专门评测模型文本到结构能力的基准:1800 个样本,跨 6 个科学领域,32 种结构类型,覆盖 45 个主流模型。关键发现:45 个模型在多跳推理上平均准确率仅 52.1%,即使最先进模型的端到端提取节点准确率也只有 58.1%。
文本结构化能力是当前 LLM 的薄弱环节,SoT 和 T2S-Bench 提供了两条互补的提升路径:前者通过提示,后者通过微调数据。
MOOSE-Star:组合复杂度从 O(N^k) 降至 O(N+k),RL 训练科学假说生成成为可能
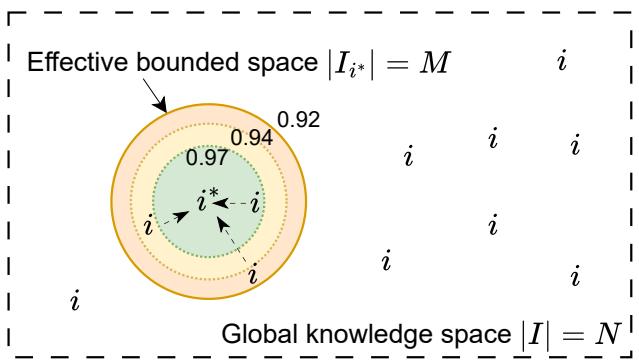
LLM 在科学发现领域正快速扩展,但直接建模 P(假说|背景) 的训练面临根本障碍:从庞大知识库中检索和组合启发信息天然具有 O(N^k) 的组合复杂度,直接训练在数学上不可行。
MOOSE-Star 提出统一框架打破这一壁垒:通过分解生成过程,最优情况下将复杂度降至 O(N+k),同时保持可扩展推理。框架支持两种互补训练策略——基于实例的 RL 与数据驱动的知识蒸馏——以及在 RLVR 设置下的融合。配套发布 TOMATO-Star 科学发现数据集和模型检查点。
这项工作为 AI 辅助科研开辟新方向:把生成式科学推理从纯推理阶段扩展到可系统训练优化的范式。
CUDA Agent:Agentic RL 攻入 GPU Kernel 领域,最难等级超越 Claude Opus 40%
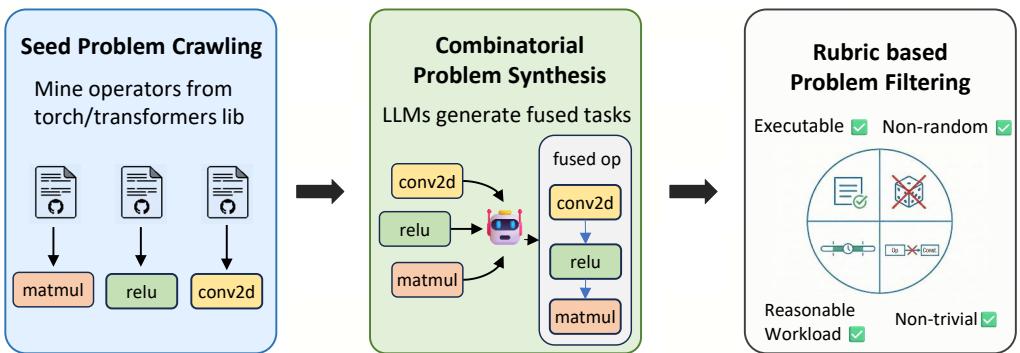
GPU Kernel 优化是深度学习基础设施的核心,需要深厚硬件知识。尽管 LLM 在通用编程上表现出色,现有方法在 CUDA Kernel 生成上仍无法与 torch.compile 竞争。CUDA Agent 是一个大规模 Agentic RL 系统,通过三个维度突破:
(1) 可扩展数据合成管线:生成广泛难度等级的训练问题,支持课程式 RL;(2) 技能增强 CUDA 开发环境:自动化验证和性能分析脚本提供可靠奖励信号,系统级隔离防止奖励作弊;(3) RL 算法稳定性:Actor/Critic 多阶段预热策略解决训练不稳定。
CUDA Agent 在 KernelBench 取得 SOTA:Level-1/2 的 100% 超越 torch.compile,Level-3 达 92%,在最难设置上超越 Claude Opus 4.5 和 Gemini 3 Pro 约 40%。这是 LLM 首次在此专业任务上实现系统性突破。
UniG2U-Bench:统一多模态模型的生成能力并未普遍提升理解——30+ 模型实证
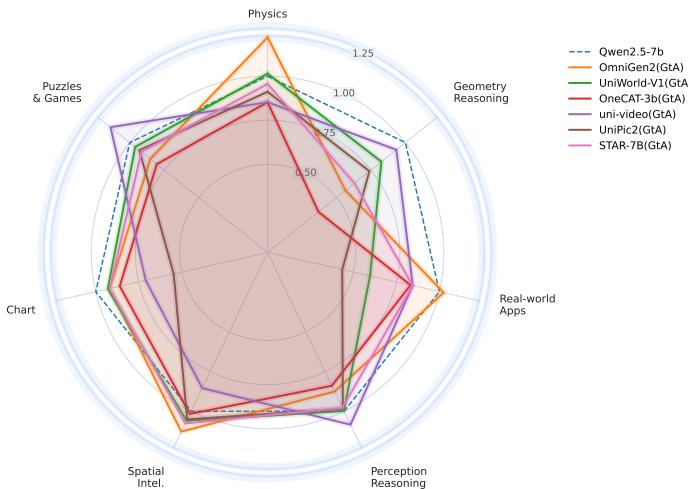
统一多模态模型(Bagel、OmniGen、Show-o 等)宣称「理解+生成一体化」带来双向互利,但生成能力是否真的提升了理解一直缺乏系统验证。UniG2U-Bench 构建了 7 大维度、30 个子任务的评测体系,严格将统一模型与其基础 VLM 配对比较。
三个核心发现:(1) 统一模型普遍不如基础 VLM,Generate-then-Answer 推理通常比直接推理更差;(2) 仅在空间智能、视觉错觉、多轮推理子任务中出现一致提升;(3) 具有相似推理结构的任务和共享架构的模型表现出相关的行为模式。
结论不是否定统一模型,而是指向更精细的训练策略需求:需要更多样化的训练数据和新范式,才能真正将生成能力转化为理解优势。
SWE-rebench V2:语言无关的 SWE 任务规模化采集管线,填补 RL 数据瓶颈
SWE Agent 的 RL 训练面临关键约束:缺乏大规模、可复现执行环境且测试套件可靠的任务集合。现有基准多针对 Python,规模有限。SWE-rebench V2 提出语言无关的自动化管线,从真实世界代码仓库大规模采集可执行 SWE 任务:
(1) 交互式安装 Agent合成仓库特定安装和测试流程;(2) LLM 集成过滤(ensemble of judges)消除不健全实例;(3) 自动适配多语言仓库,不依赖特定语言生态假设。
核心价值在于解决了 SWE Agent RL 训练的数据基础设施瓶颈,为多样化、大规模、跨语言的代码工程 Agent 训练提供了可扩展的数据供给。
Meta FAIR 多模态预训练:严格控制变量实验揭示 RAE、MoE 和视觉-语言数据协同
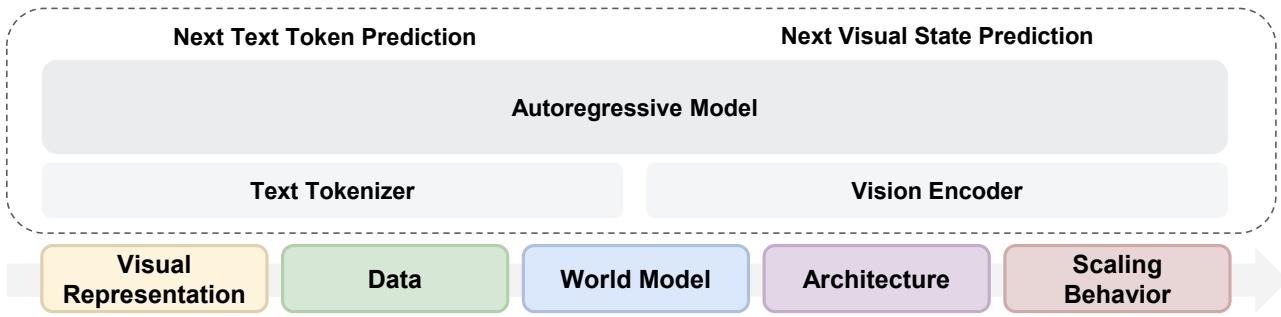
原生多模态模型的设计空间仍然不透明——哪些架构和训练选择真正重要?来自 Meta FAIR 和 NYU(Yann LeCun 参与指导)的团队,在不依赖语言预训练的前提下,通过严格控制变量的从头预训练实验系统隔离核心因素。
四个关键发现:(1) RAE(Reconstruction Autoencoder)是最优统一视觉表征,同时擅长理解和生成;(2) 视觉和语言数据联合训练产生跨模态协同;(3) 世界建模能力从通用训练自然涌现,无需专项设计;(4) MoE 架构自然诱导模态专业化,通过 IsoFLOP 分析揭示视觉比语言需要更多数据的缩放不对称性。
这项工作提供了迄今最系统的多模态基础模型从头实验指导,回答了「为什么用 RAE」「为什么用 MoE」等关键设计问题。
SkillNet:20 万+ AI 技能库——创建、评测、连接技能的统一基础设施
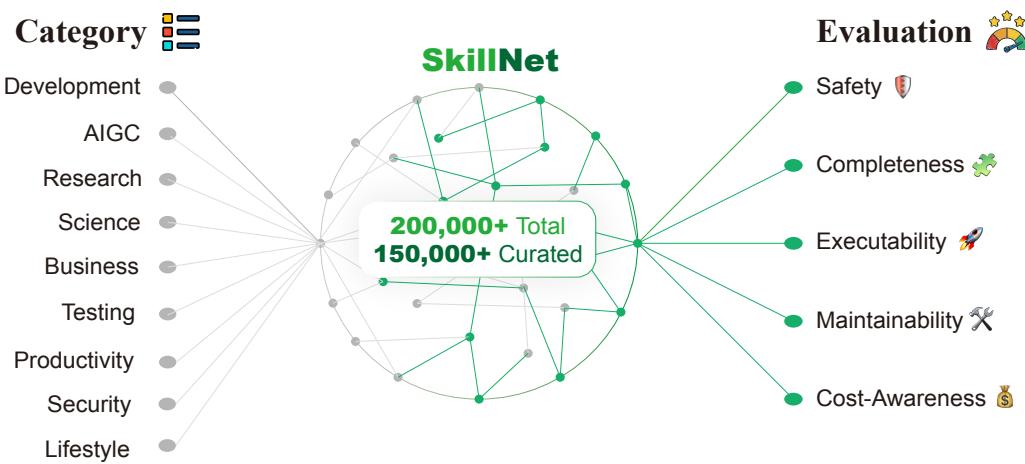
当前 AI Agent 可以灵活调用工具执行复杂任务,但长期发展受限于缺乏技能的系统性积累和迁移。没有统一的技能管理机制,Agent 频繁「重新发明轮子」——在孤立场景中重新发现解决方案,而无法复用已有策略。
SkillNet 是一个开放基础设施,将 AI 技能组织在统一本体中:支持从异构来源创建技能、建立关系连接(相似性、组合、依赖),并进行五维评测(安全性、完整性、可执行性、可维护性、成本感知)。基础设施集成了超过 200,000 个技能的仓库、交互式平台和 Python 工具包。
在 ALFWorld、WebShop 和 ScienceWorld 上的实验表明,SkillNet 将平均奖励提升 40%、执行步数减少 30%。将技能从一次性工具升级为可演化、可组合的资产,为 Agent 从「临时经验」走向「持久掌握」奠定基础。
RubricBench:能打分的模型不一定能出好题——评分标准对齐基准
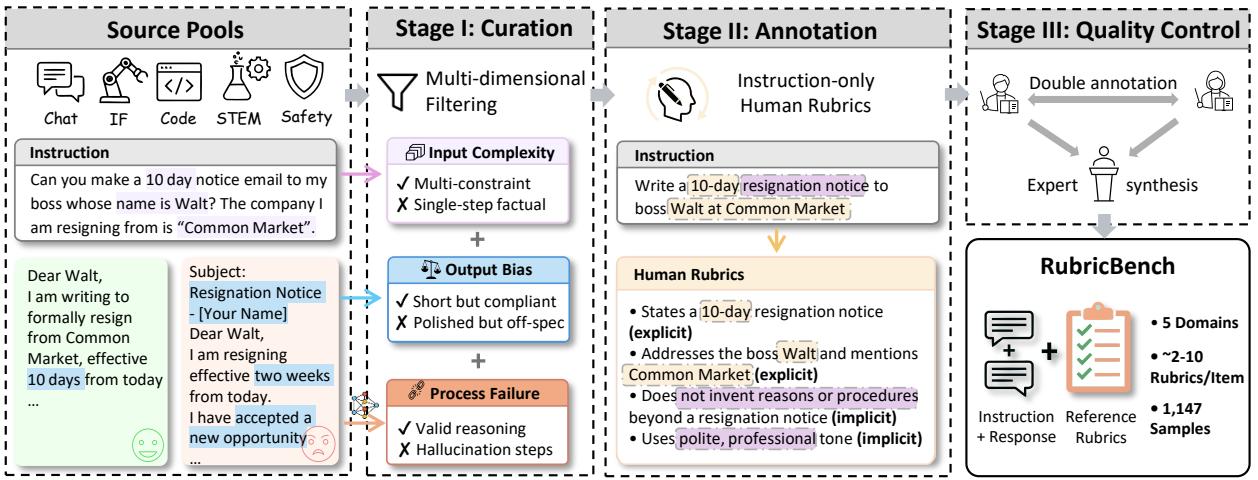
LLM 对齐越来越依赖基于 Rubric(评分标准)的评估来减轻表面偏见,但模型生成的 Rubric 与人类标准的对齐程度一直缺乏统一基准。RubricBench 填补这一空白:将「打出正确分数」与「生成对人类有意义的评分框架」这两个不同能力区分开来。
基准覆盖写作质量、代码正确性、推理链等多个维度的复杂生成任务,测试模型能否生成与人类评估者一致的评分标准。
随着 AI 评测越来越依赖 LLM-as-Judge,理解模型生成评估框架的质量与局限性变得尤为重要——对 RLHF 数据质量和 AI 对齐研究都有直接影响。
BeyondSWE:代码 Agent 走出单仓库 Bug 修复,500 个跨域任务暴露系统性能力缺口
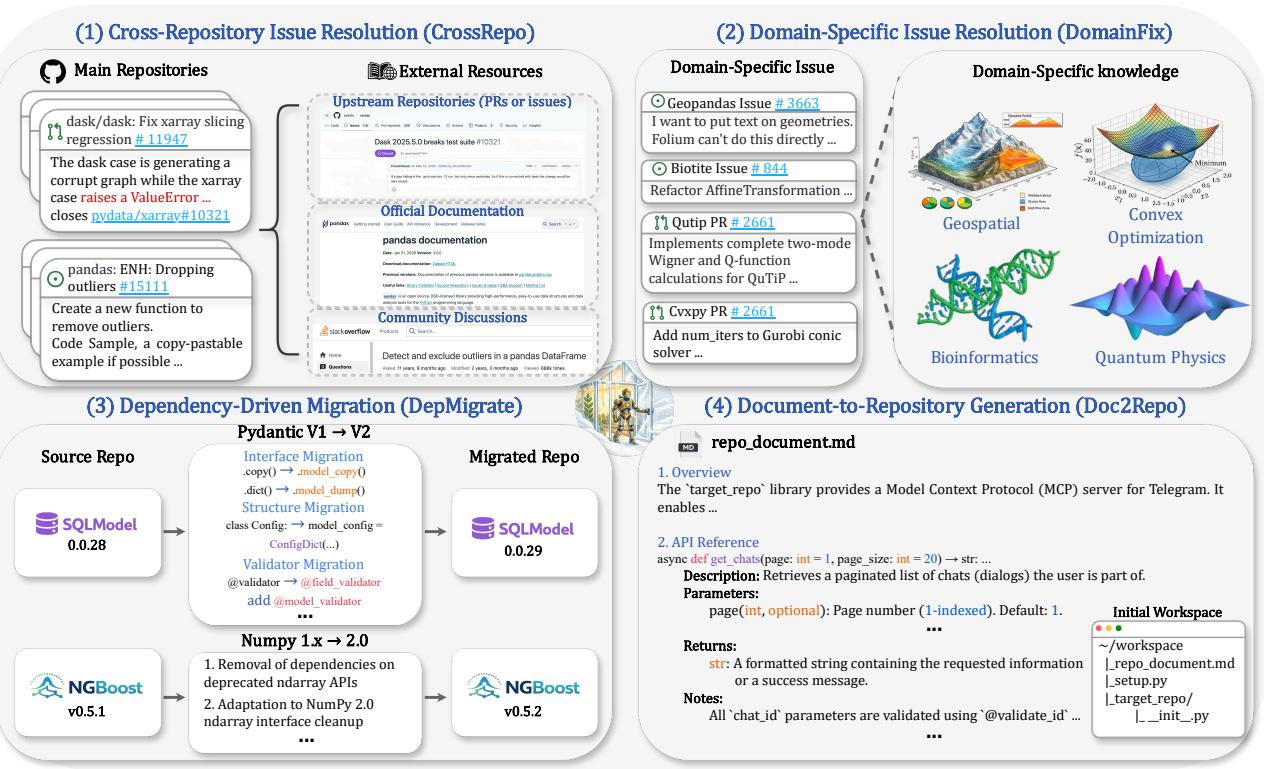
SWE-bench 的任务本质局限于单仓库内的函数级 Bug 修复。BeyondSWE 沿解决范围和知识范围两轴扩展,500 个实例覆盖四类设置:CrossRepo(跨仓库推理)、DomainFix(需领域专业知识的修复)、DepMigrate(依赖迁移)、Doc2Repo(从文档生成整库)。
即使最强前沿模型,成功率也低于 45%,且没有任何模型在所有任务类型上一致表现良好。搜索增强框架 SearchSWE 在某些任务上甚至降低性能。真实工程场景的多样性远超当前基准覆盖范围。
3月第二周值得关注的三个信号 编辑观点
-
RL 正在从「对齐对话」向「专业工程」全面扩展
CUDA Agent 攻入 GPU Kernel 优化(超越 torch.compile)、MOOSE-Star 把 RL 推向科学假说生成(O(N^k)→O(N+k))、HACRL 让异构模型在训练阶段共享推理轨迹互学——RLVR 范式正在证明它在专业工程领域的泛化能力。关键洞察:专业 RL 的瓶颈不在算法,而在领域环境和奖励信号的设计质量。
-
「统一」叙事面临实证检验的严肃挑战
UniG2U-Bench 对 30+ 统一多模态模型的系统评测显示生成能力并未普遍提升理解,BeyondSWE 暴露代码 Agent 在跨仓库场景下成功率不足 45%。但同一周 Utonia 用单编码器跨五域点云取得跨域涌现效应——矛盾之处在于:统一的价值取决于能力是否真正迁移,而非简单叠加。
-
「工具性」研究正获得社区高度认可
dLLM(扩散LM统一框架,123票)、SWE-rebench V2(语言无关SWE任务采集,77票)、SkillNet(20万AI技能基础设施,68票)分别在不同子领域填补基础设施空白。这些不追求 SOTA 的框架性工作获得的票数甚至超过许多方法论文——社区正在为「可复用、可组合」的基础设施投票。
参考链接
- [1] Utonia — arXiv:2603.03283 · HF Papers
- [2] HACRL — arXiv:2603.02604 · HF Papers
- [3] Helios — arXiv:2603.04379 · HF Papers
- [4] OmniLottie — arXiv:2603.02138 · HF Papers
- [5] ADE-CoT — arXiv:2603.00141 · HF Papers
- [6] dLLM — arXiv:2602.22661 · HF Papers
- [7] T2S-Bench & SoT — arXiv:2603.03790 · HF Papers
- [8] MOOSE-Star — arXiv:2603.03756 · HF Papers
- [9] CUDA Agent — arXiv:2602.24286 · HF Papers
- [10] UniG2U-Bench — arXiv:2603.03241 · HF Papers
- [11] SWE-rebench V2 — arXiv:2602.23866 · HF Papers
- [12] Beyond Language Modeling (Meta FAIR) — arXiv:2603.03276 · HF Papers
- [13] SkillNet — arXiv:2603.04448 · HF Papers
- [14] RubricBench — arXiv:2603.01562 · HF Papers
- [15] BeyondSWE — arXiv:2603.03194 · HF Papers
感谢你读完这份周报。本周 151 篇论文中,RL 的专业化扩展势不可挡——从 GPU Kernel 到科学假说到异构 Agent 协同;「统一」叙事在实证检验中显现裂缝,但也孕育着更精细的解法;基础设施建设正成为社区投票的新宠。
下周重点关注:(1) Helios 开源后视频生成实时化路线的竞争格局;(2) SkillNet 的 20 万技能库能否被其他 Agent 框架采用;(3) 异构 Agent 协同训练范式(HACRL)是否引发跟进研究潮。
如果这份周报对你有帮助,欢迎顺手点赞、在看、转发三连,让更多关注 AI 研究的朋友看到。想第一时间收到下周周报,记得给公众号加个星标。
© 2026 AI Insight · 机智流 · 本文由 AI 生成,可能有误